Ретроспективный» означает, что система вычисляет значение слова или фразы, основываясь на предыдущих значениях в последовательности. Это позволяет системе учитывать контекст и правильно выбирать между различными переводами.
Разработка алгоритма нечёткого поиска в распознанном тексте
Сегодня системы автоматического визуального распознавания текста с помощью нейронных сетей показывают очень высокие результаты в точном распознавании символов. Однако инженерам-исследователям пока не удалось достичь 100% точности. Поэтому проблемы поиска информации и исправления ошибок в распознанных текстах продолжают волновать научное сообщество, а также исследования и разработки. Эти проблемы можно решить путем корректировки текста с использованием лексикона или языковой модели языка, на котором был создан текст. В частности, для извлечения информации используются языковые модели word2vec и сети SiamLSTM.
В рамках проекта по разработке системы распознавания регистров на основе изображений мы занялись проблемой поиска информации в распознанном тексте. Наше исследование стало новым шагом на пути к повышению эффективности распознавания текста.
1.Определение проблемы получения информации в распознанном тексте2.Применение эвристических алгоритмов3.Выбор методов машинного обучения в качестве приоритетных4.Использование полностью когерентной нейронной сети для решения проблемы5.Применение итеративной LSTM нейронной сети для решения проблемы.
Постановка задачи поиска информации в распознанном тексте
После применения системы распознавания текста к кассовому чеку мы получили серию распознанных текстов с некоторыми искажениями. Логическим продолжением нашей задачи было найти нужную информацию из распознанных текстов.
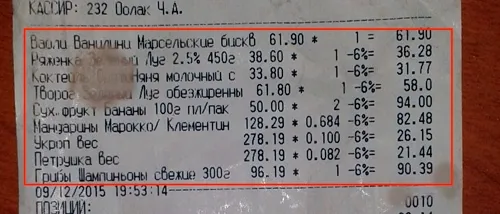
Задача в данном случае — извлечь из текста некоторые данные (например, списки покупок, номера НДС, даты и т.д.). Тексты на изображении распознаются с ошибками. Изображения текстов, признанных расписками, ясно показывают, что Рисунки 1 и 2, которые также проиллюстрированы на рисунках 3 и 4, где показаны сегменты рынка и маркированные рынки соответственно.
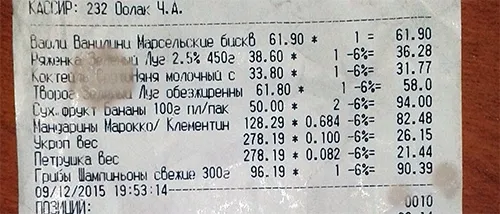
Рисунок 1. Пример пробного изображения с текстом

РИСУНОК 2. Пример распознанного текста

Применение эвристического алгоритма
Во-первых, для извлечения информации из искаженного текста после распознавания был выбран эвристический алгоритм. Эвристические методы — это регулярные выражения и сложные алгоритмические структуры. По нашему мнению, они были достаточны для решения задачи извлечения необходимых данных из текста. Однако на практике этот подход оказался недостаточно гибким и слишком сложным. По мере поиска все более сложных элементов управления нам нужно было создавать все более сложные и запутанные эвристики.
Следующим шагом было отойти от этого подхода и рассмотреть альтернативные варианты, например, попробовать использовать методы машинного обучения для решения проблемы.
Нейронные сети могут успешно использоваться в системах распознавания текста, но есть существенные недостатки, которые препятствуют их широкому применению.
Тонкости нейронного перевода: как это работает
Нейронные модели автоматического перевода используют иные принципы обработки текста, чем стандартные методы статистического перевода.
До появления нейронных сетей перевод осуществлялся слово за словом. Система переводит отдельные слова или фразы на основе грамматики. Качество перевода было низким для сложных выражений и длинных предложений.
GNMT, с другой стороны, переводит целые предложения, учитывая контекст. Система не запоминает сотни вариаций фразы — она работает с семантикой текста.
После перевода предложения оно анализируется на лексические сегменты. Затем система использует специальный декодер для определения «веса» каждого участка текста. Затем вычисляется максимально возможное значение, и секция переводится. Последний этап — соединение переведенных частей с учетом грамматики.
Как использовать онбординг для роста бизнес-метрик в B2B
Это показано на примере одного из лучших примеров российской HR-технологии.
Выдержка из презентации GNMT, показывающая, как нейронная сеть переводит предложения с китайского языка на осмысленные разделы
Как действует алгоритм переводчика
Чтобы понять, как работает перевод Google Neuron, давайте немного углубимся в технические детали.
Механический перевод Neuron от Google основан на двунаправленной рекуррентной нейронной сети, работающей по таблицам вероятностей.
Давайте рассмотрим подробнее, что это значит.
Ретроспективный» означает, что система вычисляет значение слова или фразы, основываясь на предыдущих значениях в последовательности. Это позволяет системе учитывать контекст и правильно выбирать между различными переводами.
Например, во фразе «mayon» система переводит «лук» как «лук», а не как «лук».
Два направления означают, что нейронная сеть разделена на два потока — разрешения и композиции. Каждый поток состоит из восьми слоев, выполняющих векторный анализ.
Первый поток разделяет предложение на семантические элементы и анализирует их, а второй поток вычисляет наиболее вероятный перевод на основе модулей окружения и внимания.
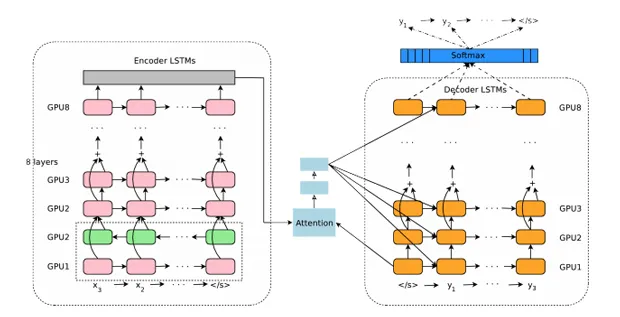
Обратите внимание, что сеть анализа «читает» предложения не только слева направо, но и справа налево, чтобы полностью понять фрейм. Кроме того, второй поток порождает отвлечение внимания на понимание ценности отдельных семантических фрагментов.
В нейронных системах мельчайшими элементами являются не слова, а фрагменты слов. Это позволяет сосредоточить вычислительную мощность на контексте и смысле предложения, а не на форме слова. GNMT использует около 32 000 таких фрагментов. По словам разработчиков, это позволяет осуществлять более быстрые и точные переводы без больших затрат вычислительной мощности.
Анализ отрывков значительно снижает риск неточного перевода слов и фраз с различными ситуациями, проблемами и окончаниями.
Система Self -Defence позволяет нейронной сети точно переводить термины, которых нет в установленных словарях, такие как сленг, жаргон и неологизмы.
Но это еще не все. Нейронные сети также могут оперировать буквами. Например, для переноса имени из одного алфавита в другой.
Статистика: действительно ли стало лучше?
Поскольку система GNMT находится на рынке уже два года, можно оценить результаты.
Почему сейчас; дело в том, что нейронные системы работают без установленной базы данных, и требуется время для создания и адаптации методов перевода.
Например, создание модели автоматического перевода с использованием статистических методов длится от одного до трех дней. Между тем, создание модели нейронов такого же размера занимает более трех недель.
Стоит отметить, что с увеличением базы время обработки для статистических моделей увеличивается численно, а для нейронных сетей — в геометрической прогрессии. Чем больше база, тем дольше временная задержка.
Кроме того, учитывая, что Google Translate работает с 10 000 пар языков (103 языка), очевидно, что правильные результаты могут быть обобщены.
В ноябре 2016 года, после того как система была полностью обучена и официально запущена, аналитики Google представили подробный анализ результатов GNMT. Это показывает, что улучшение точности перевода незначительно и составляет в среднем 10%.
Наиболее популярные языковые пары, такие как испано-английский и французско-английский, показали наибольшее улучшение, ровно 85-87%.
В 2017 году компания Google провела масштабный опрос среди пользователей Google Translate, попросив их оценить три варианта перевода: машинная статистика, нейроны и человек. Здесь результаты оказались более интересными. Перевод на несколько пар языков с помощью нейронной сети оказался очень близок к человеческому переводу.
| Статистическая модель | Нейронная сеть | Человеческий перевод | |||
|---|---|---|---|---|---|
| Английский — Испанский | 4,885 | 5,428 | 5,550 | ||
| Английский — Французский | 4,932 | 5,295 | 5,496 | ||
| Английский — Китайский | 4,035 | 4,594 | 4,987 | ||
| Испанский — Английский | 4,872 | 5,187 | 5,372 | ||
| Французский — Английский | 5,046 | 5,343 | 5,404 | ||
| Китайский — Английский | 3,694 | 4,263 | 4,636 |
За основу взята шестибалльная система оценки качества перевода. 6 — максимальная оценка, 0 — минимальная оценка.
Как вы можете видеть, качество переводов языков очень близко к человеческому для пар английский-французский-английский. Однако в этом нет ничего странного — это пары языков, в которых происходило глубокое обучение.
Результаты для тех же графиков показаны ниже. Это наглядно демонстрирует отличие от стандартного автоматического перевода.
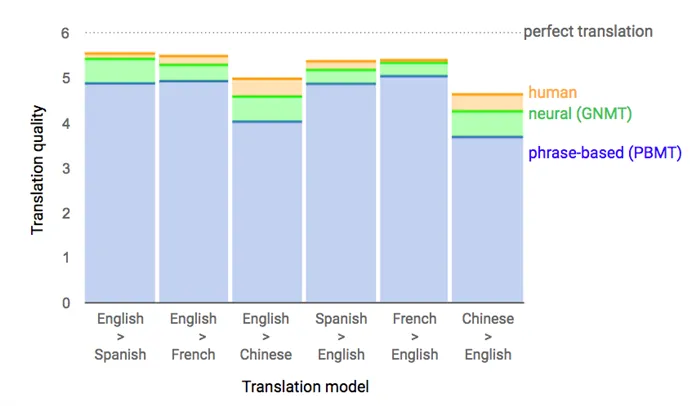
Для других языковых пар ситуация не так хороша, но масштабных исследований по ним нет. Однако нейронный перевод очень хорошо работает для структурно схожих языков, но его очень не хватает для перевода людей с радикально разными языковыми системами (например, японский и русский).
Однако стоит отметить, что разработчики не пытались добиться максимальной точности перевода при запуске нейронной сети. Это связано с тем, что для этого требуются сложные эвристические структуры, которые снижают скорость работы системы. Разработчики попытались найти баланс между точностью и скоростью. На наш субъективный взгляд, им это удалось.
Второй подход не использует вспомогательные функции, а моделирует процесс распознавания органических систем. Сегодня этот подход кажется более перспективным.
Применение систем распознавания текстов править
Системы OCR используются во многих областях. Некоторые из задач, которые необходимо решить системе идентификации текста: — как распознать символы в тексте.
- Считывание данных с бланков и анкет.
- Автоматическое распознавание номерного знака.
- Распознавание паспортных данных.
- Извлечение информации из визитных карточек в список контактов.
- Создание цифровых версий печатных и рукописных документов, например, сканирование книг для проекта «Гутенберг» 4 .
- Технология для помощи слепым и слабовидящим.
Наиболее распространенные задачи OCR править
Следующая проблема связана с задачей распознавания символов.
- Разнообразие форм начертания символов: документ может содержать несколько шрифтов сразу, а символы могут быть схожи по начертанию.
- Искажение изображения, содержащего текст:
- Шумы при печати.
- Плохое качество изображения (засвеченность, размытость).
Процесс распознавания текста править
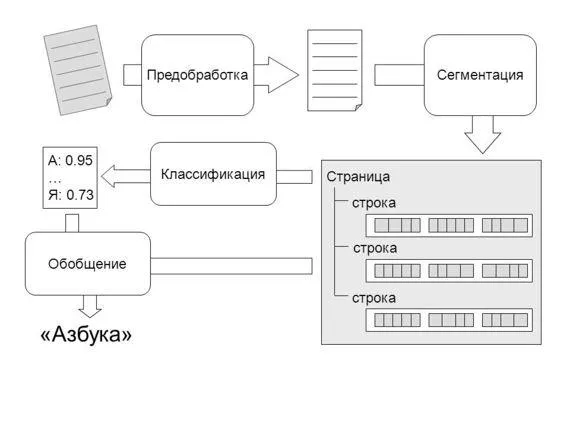
Системы идентификации текста предполагают, что на вход подается текстовое изображение (в виде графического файла данных). На выходе система должна выдать текст, извлеченный из входных данных. Весь процесс распознавания текста состоит из различных задач.
Обработка изображения править
Прежде чем приступить к распознаванию текста, изображение должно быть уменьшено таким образом, чтобы оно не содержало шумов и позволяло эффективно экспортировать и распознавать символы. Как правило, изображение повышается резкость, контрастность, выравнивается и преобразуется в формат системы (например, 8-битная шкала серого).
Распознавание символов править
Эти результаты достигаются благодаря использованию нейронных сетей, которые представляют собой специализированные системы искусственного интеллекта, функционирующие аналогично человеческому мозгу. Нейронные сети также могут обучаться. Конечно, это не интегрированный искусственный интеллект, но это обучающаяся система.
Предобучение и дообучение нейросети
В сложных нейронных сетях обучение делится на две части («до обучения» и «после обучения» («улучшения»)). Это как степень и степень магистра в области нейронных сетей. На первом этапе много ресурсов и времени должно быть потрачено на предоставление «общих знаний». На втором этапе вы можете тренироваться для решения конкретных задач.
Предварительное обучение является базовым и дорогостоящим. Требуется множество различных наборов данных. Гири могут быть случайными или даже пустыми и должны быть заполнены чем-то значимым. Нейронную сеть легко «воспитать» (или «усовершенствовать»). Распространенный и простой способ — сбросить последний слой шкалы, обучить нейронную сеть на новом небольшом наборе данных и выполнить новую задачу (не ту, которая была получена до обучения).
В случае с Бертом это выглядит следующим образом. Сначала модель долго обучали угадывать, какие слова отсутствуют в одном предложении, и если два предложения следовали друг за другом и были получены новые данные, то создавался новый пустой слой нейронов и получались новые данные. Его попросили понять, какие вопросы на Quora были об одном и том же. Процесс пост-обучения зависит от работы и типа нейронной сети, выше описаны лишь очень общие идеи.
Чем BERT отличается от предшественников
Инновация Bert заключается главным образом в способе предварительного нагрева. Предыдущие архитектуры выполняли работу по производству текстов для того, чтобы пройти обучение. То есть, учитывая все предшествующие слова, он предсказывал, какое слово, скорее всего, будет следующим. Только левое слово влияло на решение нейронной сети (и таким образом, например, функционировало в трансформаторе Openai) — такая нейронная сеть называется однонаправленной. Мужчины так не поступают. Обычно мы рассматриваем все предложения одновременно.
Для решения этой проблемы были изобретены двухсторонние нейронные сети. По сути, две одинаковые нейронные сети работают параллельно, одна из которых предсказывает слова слева направо, а другая — справа налево. Затем результаты обеих сетей просто «складываются». Эта идея лежит в основе модели ELMO. Двухсторонняя нейронная сеть лучше односторонней для ряда задач, но это не совсем то, что мы хотим увидеть. Делать.
Поэтому Барт предварительно обучен «модели покрытого языка». Его суть заключается в том, чтобы предсказывать слова где-то в середине, а не в конце предложения. ‘Мужчина пошел в магазин’. Но «человек пошел за молоком». Искомые символы заменяются на маскированные символы, поэтому вызывается модель с маской.
Такой подход к обучению позволил нам сделать то, что мы не могли сделать с трансформатором. Представляйте (и учитывайте) все части фразы, а не только левое или правое слово. Открыть все предложение для одного направленного трансформатора означает дать немедленный ответ системе, которая затем пытается угадать, что это такое, и таким образом ничему не учится. (О том, как работают трансформаторы, я писал здесь). Новый метод обучения — это «глубокая двойная операция». Здесь модель не растворяет отдельные представления об окружающей среде слева направо, а рассматривает оба направления.
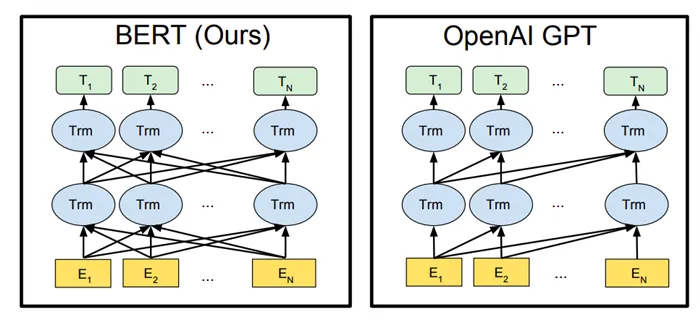
Сравнение методов работы BERT и GPT: односторонние и двусторонние сети
Берт «внизу» имеет механизм внимания, который намеренно похож на соответствующий механизм транс-ГПТ, чтобы облегчить сравнение результатов. Архитектура похожа. Чтобы упростить его, Берт увеличил количество и размер уровней, убрал раздел декодирования и научился рассматривать рамки в обоих направлениях. Внимание в простом трансформаторе всегда обращается на левую фишку заданного (правое слово заменяется специальным словом, обнуляющим вес внимания). Берт, с другой стороны, «покрывает» только то, что должно быть предсказано. Это означает, что внимание уделяется всем частям последовательности входа как с левой, так и с правой стороны.
Машина внимания умеет определять множители, которые повышают серьезность важных слов в ящике. Это значительно повышает точность решений, принимаемых нейронной сетью. Мы ранее информировали вас о работе этого механизма.
Предобучение BERT в деталях
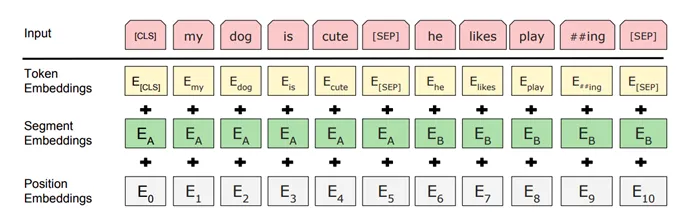
Помимо угадывания слов в середине предложения, во время обучения Барт также должен «сказать», следует ли второе предложение в учебном примере за первым. Каждый учебный пример состоит из двух пропущенных слов, и задача, поставленная перед Бартом, состоит в том, чтобы угадать, какое слово пропущено (называя цифровой код), и сказать, соответствует ли второе предложение первому. Для этого к первоначальной интеграции слов добавляется частичная интеграция частей и интеграция мест.
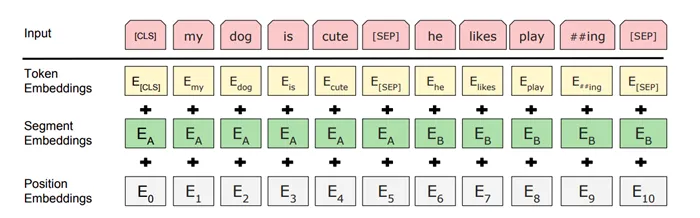
Желтая начальная интеграция слова — это число, которое является идентификатором символа системы фрагментов слова. Словарь фрагментов слов содержит 30 000 ключевых слов, отобранных создателями Berta. Среди них — самые популярные английские слова и отдельные слоги.
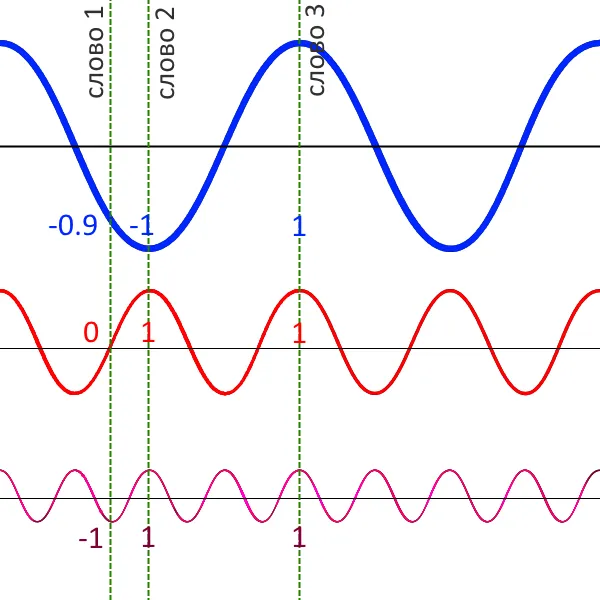
Каждая начальная интеграция сопровождается числом, указывающим, находится ли это слово в первом или втором предложении (частичная интеграция), и третьим числом, указывающим, насколько далеко друг от друга находятся эти два слова (позиционная интеграция). Последнее необходимо, поскольку транс (лежащий в основе барта) получает весь обучающий пример и работает со словом. В модели не существует «прошлого кадра». Это относится к ретроспективным нейронным сетям. Здесь следующий шаг не может быть выполнен без предыдущего (о ретроспективных нейронных сетях мы писали здесь), но трансформатор не является ретроспективной архитектурой. Bert требует вектор положения. Ему нужен набор табличек «быстро» и «медленно», причем каждый купон меняет цену. Если два слова имеют разные значения для быстрого графика, но одинаковое значение для медленного графика, они являются смежными. Если у них разные значения для медленного графика, то слова находятся далеко друг от друга.
Перед предложением, перед «сортировкой» CLS: предсказывая его, нейронная сеть угадывает, связаны ли предложения примера друг с другом (т.е. классифицирует их как «связанные» или «несвязанные»). Само предложение отделено от символов SEP, в котором некоторые слова заменены символами маски. Нейронная сеть должна предсказать наиболее вероятное слово в этой позиции.
Модель языковой маски — это компромисс. Он не должен охватывать слишком много слов (если все охвачены, то нет основы обучения) или очень мало (необходимо представить много примеров обучения). Обычно принимается решение заменить 15% слов случайно выбранной «маской».
ВАЖНО: Предварительная работа — это не работа в реальном мире. Настоящая проблема решается в нейронной сети предварительного обучения; в реальном мире не существует слов-масок. Таким образом, модель не только ищет везде, но и покрывает 80% фактической маски (смена маски) от всех слов, выбранных для замены, поэтому оставшиеся 10% заменяются на случайные слова, а 10% остаются неизменными.