В переводе из блога DeepMind команды AlphaStar рассказывается, как они научили ИИ играть в StarCraft.
AlphaStar: освоение навыков игры в стратегию в реальном времени StarCraft II
Добро пожаловать на перевод статьи команды AlphaStar в блоге DeepMind о том, как они научили ИИ играть в StarCraft.
На протяжении десятилетий игры были одним из основных способов тестирования и измерения производительности систем искусственного интеллекта. По мере расширения возможностей ИИ исследовательскому сообществу приходилось искать все более сложные игры, в которых для решения как научных задач, так и проблем повседневной жизни игрок использовал бы различные элементы интеллекта. В последние годы StarCraft, считающаяся одной из самых сложных стратегий в реальном времени (RTS) и одной из самых популярных киберспортивных игр всех времен, получила широкое признание как «серьезный вызов» для исследований в области искусственного интеллекта.
Мы хотели бы представить нашу программу для игроков StarCraft II, AlphaStar, первый ИИ, победивший лучшего профессионального игрока-человека. В серии тестовых матчей, проведенных 19 декабря, AlphaStar решительно победил Гжегожа «MaNa» Коминца из Team Liquid, одного из сильнейших профессиональных игроков в StarCraft в мире, со счетом 5: 0. До этого AlphaStar победил товарища по команде MaNa Дарио «TLO» Вюнша в историческом матче. Условия были такими же, как и в обычных профессиональных матчах, игроки соревновались на соревновательной карте и без каких-либо игровых ограничений.
Несмотря на замечательный успех ИИ в видеоиграх на платформе Atari, Mario, Quake III Arena — Capture the Flag и Dota 2, методы искусственного интеллекта еще не смогли справиться со сложностью StarCraft. Наилучший из полученных результатов был достигнут только благодаря целенаправленной «доработке» основных элементов системы, значительному ограничению правил игры, наделению системы искусственного интеллекта сверхчеловеческими способностями и благодаря игре на упрощенных картах. И даже с этими изменениями ни одна система искусственного интеллекта не смогла составить конкуренцию профессиональным геймерам. Напротив, AlphaStar воспроизводит полную версию StarCraft II, используя глубокую нейронную сеть, обученную на необработанных игровых данных посредством контролируемого обучения и обучения с подкреплением.
StarCraft как вызов
Действие игры StarCraft II, созданной Blizzard Entertainment, происходит в вымышленной научно-фантастической вселенной. Его богатый, многослойный игровой процесс был создан, чтобы сбить с толку человеческий интеллект. Наряду с оригинальным названием это одна из самых громких и успешных игр всех времен. Киберспортивные турниры проводятся более 20 лет.
Есть несколько способов сыграть в нее, но в киберспорте наиболее распространены турниры 1 × 1 на 5 игр. Для начала игрок должен выбрать одну из трех инопланетных «рас»: зергов, протоссов или терранов. Каждая раса имеет отличительные характеристики и свой собственный набор навыков (хотя профессиональные игроки обычно специализируются на одной из рас). У каждого игрока в начале игры есть разные рабочие юниты (юниты), которые собирают ресурсы, а затем строят больше юнитов и структур, создают новые технологии. Как только это будет сделано, можно будет собирать больше ресурсов, создавать более сложные базы и структуры и развивать новые возможности, чтобы перехитрить врага. Чтобы выиграть, игрок должен тщательно обдумать общую картину экономики (известную как «макро»), а также управление отдельными юнитами (этот план игры известен как «микро»).
Балансирование краткосрочных и долгосрочных целей и адаптация к непредвиденным ситуациям — сложная задача для систем искусственного интеллекта, которые могут быть негибкими и часто выходить из строя. Для решения этой проблемы необходимы инновации в нескольких областях исследований ИИ, в том числе в следующих:
- Теория игр: StarCraft — игра «камень-ножницы-бумага», в которой нет единственной лучшей стратегии. Поэтому в процессе обучения ИИ необходимо постоянно осваивать новые игровые стратегии, расширять границы стратегических знаний.
- Несовершенная информация: в отличие от шахмат и го, где игроки видят все, в StarCraft много важной информации скрыто от игрока. Он должен исследовать это в процессе «разведки».
- Долгосрочное планирование: как и во многих других действиях в реальном мире, эффекты причинно-следственной связи не проявляются сразу. Игра может длиться до часа, а это значит, что действия, предпринятые в начале игры, могут не окупиться в долгосрочной перспективе.
- Действие в реальном времени: в отличие от обычных настольных игр, где игроки по очереди по очереди, в StarCraft игроки должны действовать непрерывно и параллельно по мере прохождения игрового времени.
- Большое игровое пространство: игрок должен управлять сотнями различных юнитов и зданий одновременно в реальном времени, создавая комбинационное пространство возможностей. Кроме того, действия являются иерархическими, и их можно изменять и интегрировать. В нашей параметризации игры мы насчитали в среднем от 10 до 26 возможных действий, доступных в любой момент времени.
Из-за этих очень сложных проблем сам StarCraft стал «сложной задачей» для исследований ИИ. В текущих соревнованиях по StarCraft и StarCraft II — AIIDE StarCraft AI Competition, CIG StarCraft Competition, Student StarCraft AI Tournament и Starcraft II AI Ladder — ИИ продемонстрировал прогресс с момента запуска Brood War API в 2009 году. Чтобы помочь сообществу ИИ добиться успеха Чтобы решить эти проблемы, мы с Blizzard разработали набор инструментов с открытым исходным кодом PySC2 в 2016 и 2017 годах, который включает в себя самый большой набор анонимных повторов из когда-либо выпущенных. И вот на основе проделанной работы мы объединили инженерные и алгоритмические инновации и создали AlphaStar.
Как натренирован AlphaStar
Поведение AlphaStar генерируется глубокой нейронной сетью. Он получает входные данные из (сырого) игрового интерфейса программного обеспечения (список юнитов и их свойств) и выдает последовательность инструкций — действие в игре. Более конкретно, архитектура нейронной сети применяет трансформирующее тело к единицам (точно так же, как при обнаружении соединений посредством глубокого обучения с подкреплением) в сочетании с глубоким ядром LSTM, саморегрессивной политикой в голове с помощью сети указателей) и базовыми линиями по централизованным значениям (централизованная базовая стоимость). Мы считаем, что такая продвинутая модель поможет нам найти решения для многих других проблем машинного обучения, которые требуют длительного моделирования последовательности и где требуются большие выходные пространства. Эти задачи включают перевод, языковое моделирование и визуальные представления.
AlphaStar также использует новый алгоритм многоагентного обучения. Изначально нейронная сеть обучалась с учителем на серии анонимных повторов игр, выпущенных Blizzard. Подражая им, AlphaStar изучила основные микро- и макро-стратегии, используемые игроками в лестнице StarCraft. Этот начальный агент победил интегрированный AI Elite-AI (который играет на золотом уровне для игрока-человека) в 95% игр.
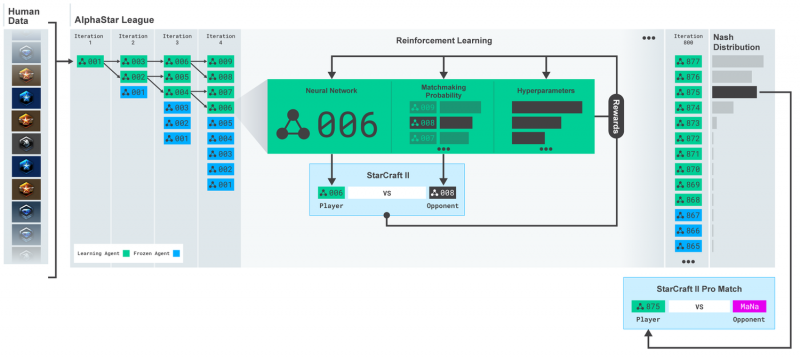
Лига AlphaStar. Агенты сначала учатся на человеческих повторах игр, а затем играют против других противников лиги. На каждой итерации новые соперники «выбиваются», исходные соперники «замораживаются», а шансы на подбор игроков и гиперпараметры, определяющие цель обучения каждого агента, могут быть скорректированы, что увеличивает сложность при сохранении разнообразия. Параметры агента обновляются с использованием обучения с подкреплением на основе игровых достижений. Конечный агент собирают (без замен) из распределения Нэша для легирующих агентов.
Затем эти агенты использовались для выполнения многоагентного обучения с подкреплением. Была создана лига с непрерывной игрой, в которой агенты лиги — соперники — играли друг против друга, как это делают люди в рейтинге StarCraft. В лигу динамически добавлялись новые соперники — выделялись из существующих игроков; Затем каждый агент учился, играя с другими игроками. Эта новая форма обучения развивает идеи многоагентного и популяционного обучения с подкреплением. Это создает процесс, который постоянно исследует обширное стратегическое пространство игрового процесса StarCraft. Это гарантирует, что каждый агент хорошо справляется с самыми сильными стратегиями и не забывает стратегии, с которыми он встречался ранее.
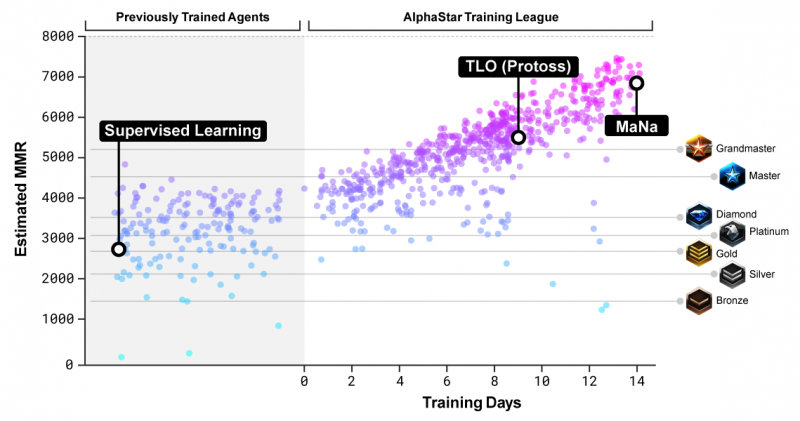
Рейтинг подбора игроков (MMR), приблизительный показатель навыков игрока, отображается для участников AlphaStar League во время периода обучения по сравнению с онлайн-лигами Blizzard.
По мере развития лиги и появления новых соперников появляются новые контр-стратегии, призванные победить предыдущие. Некоторые новые агенты берут старые стратегии и совершенствуют их, в то время как другие создают новые, состоящие из новых заказов на строительство, составов юнитов и планов микроменеджмента. Например, на ранних стадиях AlphaStar League часто предпочитали неоригинальные стратегии, такие как очень быстрая стрельба из фотонных пушек или использование темных храмовников. По мере развития процесса обучения эти рискованные стратегии отбрасывались и появлялись новые: например, получение экономической мощи за счет беспрецедентного расширения базы с большим количеством рабочих или пожертвование двух оракулов, чтобы негативно повлиять на рабочих и экономику врага. Этот процесс обучения похож на то, как игроки-люди изучали новые стратегии и побеждали предыдущие за годы, прошедшие с момента выпуска StarCraft.
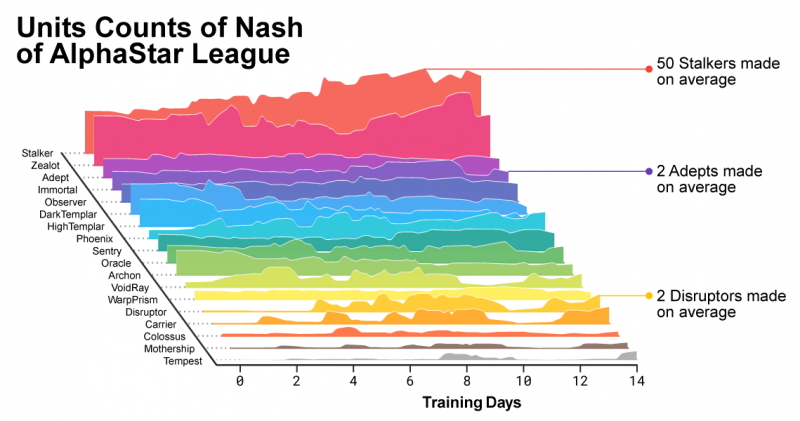
По мере развития AlphaStar League состав создаваемых юнитов менялся.
Чтобы способствовать разнообразию в лиге, каждому агенту была поставлена другая цель обучения: например, каких противников он должен победить; также могут быть указаны любые другие внутренние причины, влияющие на игру агента. Таким образом, некоторые агенты могут преследовать цель победить определенного противника, а другому может быть поручено победить все распределение агентов, но это может быть сделано только путем создания более конкретных игровых единиц. Эти цели были адаптированы во время обучения.
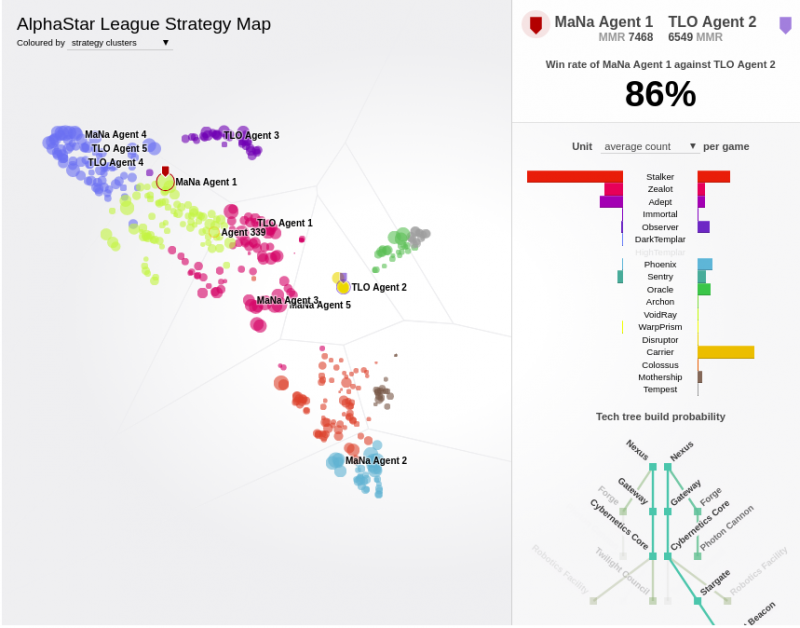
На дисплее отображаются противники в лиге AlphaStar. Особо отмечаются агенты, игравшие против MaNa и TLO. Интерактивную версию визуализации можно найти здесь: https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
На основе результатов матчей с целевыми оппонентами в обучении с подкреплением веса нейронной сети каждого агента обновляются, и, таким образом, его личная цель обучения оптимизируется. Правило обновления веса — это эффективный и новаторский алгоритм обучения критически важному для актора подкреплению вне политики с повторением опыта, обучением путем имитации и политикой дистилляции (дистилляции политики).
На рисунке показано, как агент, который в конечном итоге был выбран для игры против MaNa (обозначен черной точкой), разработал свою стратегию во время обучения (показано относительно противников, обозначенных цветными точками). Каждая точка представляет члена AlphaStar League. Положение точки определяет стратегию агента (смещение), а ее размер показывает, сколько раз он был выбран в качестве оппонента для агента, за который MaNa играл во время обучения.
Для обучения AlphaStar мы создали масштабируемую распределенную систему обучения с использованием процессоров Google Tensor TPU v3, которые поддерживают обучение всего набора агентов на многих тысячах одновременных экземпляров StarCraft II. AlphaStar League работала на процессорах в течение 14 дней, при этом каждому агенту было назначено 16 TPU. Во время обучения каждый агент получил опыт, эквивалентный 200 годам игровых лет. AlphaStar End Agent состоит из компонентов распространения Nash League — набора наиболее эффективных обнаруженных стратегий — которые могут работать на одном графическом процессоре настольного компьютера.
Полное техническое описание этой работы будет опубликовано в рецензируемом журнале.
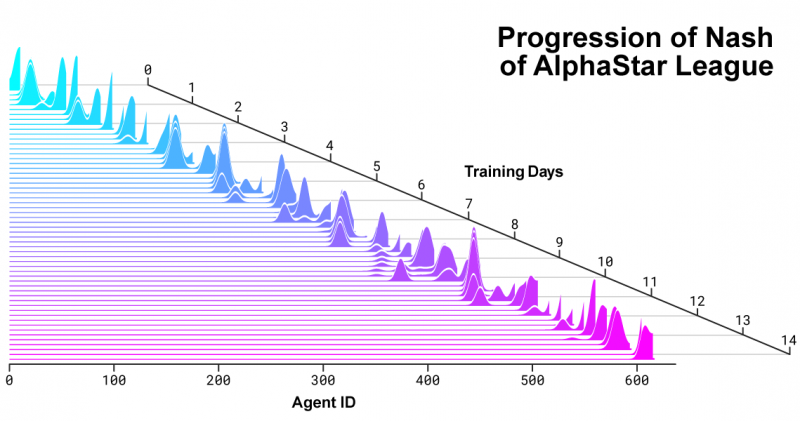
Распределение соперников Нэша по мере развития AlphaStar League и появления новых соперников. В распределении Нэша, которое представляет собой дополнительный набор соперников с наименее используемыми стратегиями, новые соперники занимают более высокий рейтинг, таким образом демонстрируя устойчивый прогресс по сравнению с ранее созданными конкурентами.
Как AlphaStar играет и как наблюдает за игрой
Профессиональные игроки в StarCraft, такие как TLO и MaNa, могут выполнять в среднем сотни действий в минуту (APM). Это намного меньше, чем у большинства существующих игровых роботов, которые управляют каждым юнитом независимо и поддерживают уровень 1000 или даже 10 000 APM.
В матчах против TLO и MaNa AlphaStar имел средний APM около 280, что значительно ниже, чем у профессиональных игроков, хотя действия AlphaStar могут быть более точными. Отчасти это связано с тем, что AlphaStar начинала с использования повторов, а затем имитировала человеческую игру StarCraft. Кроме того, AlphaStar имеет задержку между наблюдением и реакцией на события — в среднем 350 мс.
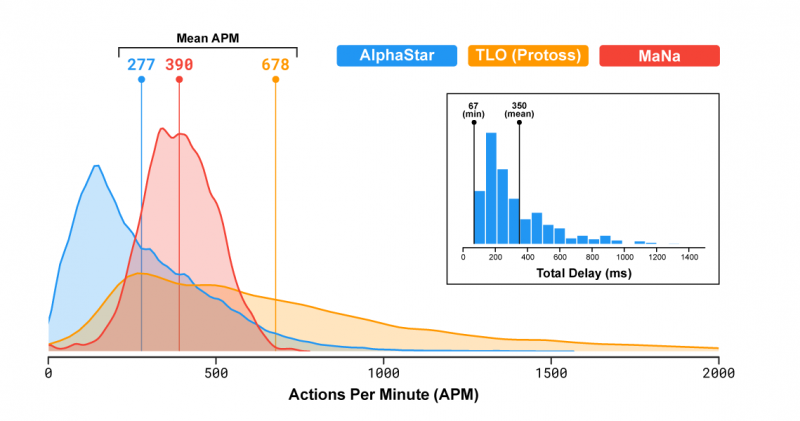
Распределение числа действий в минуту (APM) AlphaStar в матчах против MaNa и TLO, а также общая задержка — время от наблюдения до действия. ОБЪЯСНЕНИЕ (29.01.19): APM TLO превосходит AlphaStar и MaNa в том, что он использует горячие клавиши для быстрого огня, а также сочетания клавиш для «удалить и добавить в группу проверки». Также обратите внимание, что фактические всплески APM AlphaStar иногда превышают таковые у двух других игроков.
Во время матчей против TLO и MaNa AlphaStar взаимодействовала с игровым движком StarCraft напрямую через необработанный интерфейс. Это означало, что он мог наблюдать свойства своих юнитов и вражеских юнитов, видимых на карте, без увеличения и без необходимости перемещать камеру. Вместо этого люди-геймеры должны отточить свою «экономию внимания», чтобы решить, на что направить камеру. Однако анализ игр с AlphaStar показывает, что он имеет неявный фокус внимания. В среднем его агенты «переключают контексты» примерно 30 раз в минуту, как MaNa или TLO.
После этих игр мы также разработали вторую версию AlphaStar. Как и люди-геймеры, эта версия AlphaStar выбирает, когда и куда перемещать камеру. Его восприятие ограничено информацией, отображаемой на экране, а действие ограничено видимой областью карты.
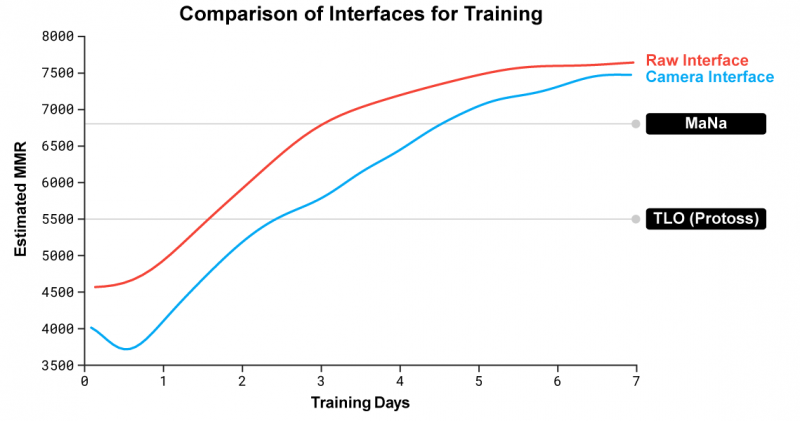
Сравнение производительности AlphaStar с использованием API с производительностью интерфейса камеры показывает, что недавно обученный агент камеры быстро достиг и почти выровнял производительность с агентом API.
Мы обучили двух новых агентов, один из которых использовал API, а другой должен был научиться управлять камерой [в играх] против [агентов] лиги AlphaStar. Изначально каждый агент был обучен посредством обучения с учителем на основе повторов игры с учителем. Затем их обучали обучению с подкреплением, как описано выше. Версия AlphaStar, использующая интерфейс камеры, заняла первое место в нашем внутреннем рейтинге с рейтингом MMR (рейтинг подбора игроков) и была почти такой же сильной, как версия, использующая API. В показательном матче MaNa победил прототип AlphaStar, который использует фотоинтерфейс и тренировался всего за 7 дней. В ближайшем будущем мы надеемся оценить полностью обученный AlphaStar с интерфейсом камеры.
Результаты показывают, что успех AlphaStar в игре против MaNa и TLO на самом деле был обусловлен его лучшим макро- и микростратегическим процессом принятия решений, чем у людей, а не скоростью кликов, коротким временем реакции или вызовами интерфейса программирования игры.
Сравнение игры AlphaStar с игрой профессиональных игроков
StarCraft позволяет игрокам выбирать одну из трех инопланетных рас: терранов, зергов и протоссов. Мы решили, что AlphaStar будет специализироваться на протоссов, когда сообщали результаты нашего национального чемпионата. Это позволило сократить время обучения и его вариативность. Тот же механизм обучения можно применить к любой другой породе. Наши агенты играли в StarCraft II (v4.6.2), Protoss vs. Протоссы в рейтинге CatalystLE. Чтобы оценить уровень игры AlphaStar, наши агенты сначала сыграли в TLO — лучшего профессионального игрока за зергов, играющего за протоссов на уровне гроссмейстера. AlphaStar, используя широкий спектр юнитов и строительный порядок, выиграл игру со счетом 5: 0. «Я был удивлен тем, насколько сильным был этот агент, — говорит TLO. «AlphaStar берет известные стратегии и переворачивает их с ног на голову. Агент использовал стратегии, о существовании которых я никогда не думал. Это означает, что могут быть другие новые подходы к этой игре, которые мы еще не открыли”.
Мы тренировали наших агентов еще неделю, после чего позволили им сыграть против MaNa, одного из сильнейших игроков в StarCraft II в мире, который входит в десятку сильнейших игроков за протоссов. AlphaStar снова выиграла 5: 0, продемонстрировав силу своих макро- и микростратегических навыков. «Я был впечатлен, увидев, как AlphaStar использует сложные ходы и различные стратегии почти в каждой игре. В нем был очень человечный игровой процесс, я этого не ожидал, — говорит МаНа. — Я понял, насколько мой игровой процесс основан на способности совершить ошибку врага, использовать его человеческие реакции. [AlphaStar] показал мне StarCraft в совершенно новом свете. Не можем дождаться, что будет дальше».
AlphaStar и другие сложные задачи
StarCraft — это всего лишь игра, хотя и сложная. Но мы считаем, что методы, лежащие в основе AlphaStar, можно использовать и для других видов деятельности. Например, архитектура ее нейронной сети такова, что она способна моделировать очень длинные последовательности вероятных действий на основе несовершенной информации — например, как для игр продолжительностью до часа, в которых есть десятки тысяч ходов. Каждый кадр экрана в StarCraft вставляется во входные данные для следующей итерации работы, и нейронная сеть каждый раз предсказывает последовательность действий, ожидаемых для остальной части игры. Эта фундаментальная проблема прогнозирования очень длинных последовательностей данных возникает во многих задачах повседневной жизни, таких как прогнозирование погоды, моделирование климата, понимание [естественного] языка и многие другие. Мы очень рады, что знания и опыт проекта AlphaStar позволят добиться значительных успехов в перечисленных выше областях.
Мы также считаем, что некоторые из наших методов обучения могут быть полезны для изучения возможностей ИИ в области безопасности и надежности. Одна из основных проблем с ИИ заключается в том, что существует множество возможных сценариев, в которых он может пойти не так. Профессиональные игроки в StarCraft раньше легко находили хитроумные способы вызывать ошибки и тем самым побеждать системы искусственного интеллекта. Благодаря инновационному процессу обучения, основанному на игровых лигах, AlphaStar находит наиболее надежные подходы к игре, при которых вероятность ошибки мала. Нас обнадеживает то, что этот подход может помочь повысить безопасность и надежность систем ИИ в целом, особенно в областях, где безопасность имеет решающее значение, например, в энергетике, где необходимо принимать крайние решения (сложно).
для ИИ это большой шаг вперед в достижении высочайшего уровня владения StarCraft, одной из самых сложных видеоигр в истории. Мы считаем, что в сочетании с последними достижениями в проектах AlphaZero и AlphaFold это достижение представляет собой шаг вперед в нашей миссии по созданию интеллектуальных систем, которые помогут нам решить некоторые из наиболее важных фундаментальных научных задач в мире в будущем.
Источники
- https://22century.ru/popular-science-publications/alphastar-mastering-real-time-strategy-game-starcraft-ii