Тираш — кто баллотируется? Английский язык. Есть ли личный конец? ‘run’ означает «я бегу» и «бежать». Изменение происходит только в единственном числе. Оставьте себе «тириш».
Как создать свой язык перевода в Telegram
В настройках Telegram Messenger есть большое количество опций, включая настройку, позволяющую выбрать рабочую среду. Изначально, когда приложение только появилось, оно поддерживало только английскую локализацию. Однако после значительного увеличения числа пользователей разработчики добавили поддержку многочисленных переводов. Но как я могу создать свой собственный язык в Telegram по телефону? Этот вопрос волнует многих пользователей, которые хотят адаптировать мессенджер под свои нужды. Что ж, мы подготовили пошаговое руководство, как это сделать!
Недавно Messenger Creator выпустил глобальное обновление, позволяющее обычным пользователям самостоятельно создавать любой язык. Это может понадобиться, если стандартные переводы не выполняются или выполняются очень плохо. Кроме того, благодаря гибким настройкам можно отключить чековые и появляющиеся окна в телеграммах во время собственного кризиса. Например, хорошо известная кнопка «OK» может быть заменена на «Да».
Шаг 1: авторизация и первоначальная настройка
Как вы видите, в самом мессенджере нет вкладки для создания пользовательских переводов. Поэтому вам в любом случае придется использовать браузер на смартфоне или компьютере. Вам также понадобится доступ к номеру телефона, подключенному к вашей учетной записи Telegram. Не будем слишком долго останавливаться на теории.
- Открываем веб-обозреватель и переходим по ссылке (translations.telegram.org), ведущей на сайт с созданием перевода. После чего в тексте находим гиперссылку Start Translating и нажимаем по ней. Перед вами появится небольшое окошко со всеми доступными языками. Но так как мы собрались делать свою локализацию, то выбираем Add a new language.
- В появившемся поле указываем номер телефона, привязанный к аккаунту Телеграм. Для подтверждения авторизации нажимаем Next и проверяем мессенджер.
- Там находим официальное сообщение и подтверждаем вход кнопкой Confirm. Вы также можете проверить, с какого устройства и через какой браузер выполняется авторизация. В конце возвращаемся в веб-обозреватель и повторно отмечаем Add a new language.
- Теперь непосредственно разберемся, как создать свой язык в Телеграмме на телефоне. Для этого заполним предложенную форму, указав достоверную информацию. Во-первых, вводим Short Name – название перевода. Во-вторых, Name и Native Name – обозначение языка на английском и в оригинале. И в-третьих, заполняем поле Base Language. Там указываем локализацию, которая будет использоваться по умолчанию. Например, если вы забыли перевести определенный элемент интерфейса.
- Нажимаем Save language для сохранения изменений.
На этом первоначальная настройка завершена, и вы можете приступить к переводу Telegram.
Шаг 2: создание своего языка
Следующий шаг — создание языковых переводов. Следует отметить, что разработчики действительно постарались, добавив отдельные опции для каждой платформы. Это позволяет им создавать различные места для Android, iOS, MacOS и Windows. Однако остановитесь на первом предложении, поскольку большинство людей используют телеграммы со своих мобильных телефонов. Чтобы избежать ошибок, рекомендуется следовать пошаговым инструкциям.
- Выбираем, для какого устройства будем делать перевод. Отмечаем нужную платформу, а затем жмем кнопку Start Translating.
- Указываем категорию, с которой планируем начать. Если вы решили полностью перевести весь интерфейс, то придется постараться. Дело в том, что общее количество действий – более 2000! Поэтому советуем начать с самого важного, расположенного в группах Log In, Chat List и Profile.
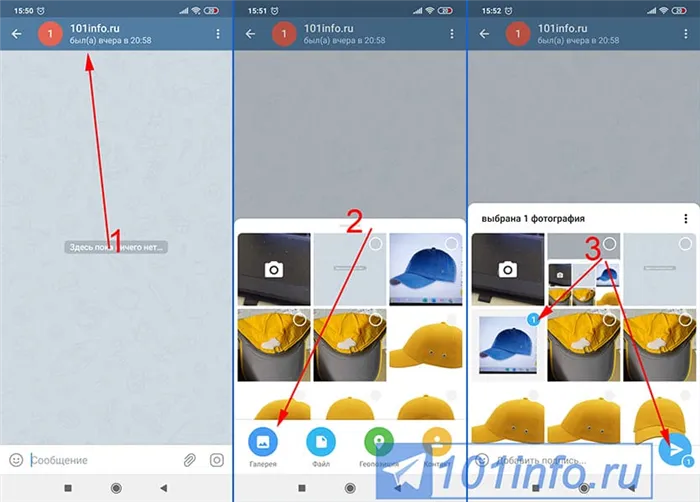
- На следующей странице видим список, состоящий из различных действий. Также присутствует картинка, показывающая, какое слово или предложение будет переводиться. И для того, чтобы создать свой язык в Телеграмме на телефоне, нажимаем по любому варианту.
- В графу Add Translating вписываем конечный перевод. Не забываем сохранить изменения, нажав на кнопку Submit and Apply.
Используйте те же принципы для создания языка программирования. Только в качестве основы используется другой язык программирования, изначально объясняющий значение слов (команд). Собеседник, к которому обращено сообщение, — это компьютер с двоичной логикой.
Первые шаги
«С чего начать» — этот вопрос часто задают другие разработчики, когда узнают, что я пишу свой язык. Я постараюсь подробно ответить на этот вопрос в данном разделе.
Компилируемый или интерпретируемый?
Компилятор анализирует всю программу, преобразует ее в машинный код и сохраняет для дальнейшего выполнения. Интерпретатор анализирует и выполняет строки в режиме реального времени.
Технически, любой язык можно редактировать и интерпретировать. Однако для каждого языка один метод подходит больше, чем другой, и выбор ранних примеров определяет дальнейший дизайн. В целом, интерпретация является гибкой, а компиляция обеспечивает высокую производительность, но это вершина очень сложной темы.
Я хотел создать простой, но мощный язык для того, что существует, поэтому я решил составить Pinecone. Однако Pinecone также имеет переводчик. Сначала мне нужен был только один, чтобы управлять им. Я объясню позже.
Примечание: Это отличное упражнение для тех, кто изучает Python. Кстати, вот краткий обзор серии статей о создании собственного интерпретатора. Это отличное упражнение для тех, кто изучает Python.
Выбор языка
Своего рода мета-шаг: сам язык программирования — это программа, которая должна быть написана на этом языке. Мы выбрали C ++ из-за его производительности, хороших характеристик и потому, что он нам понравился.
Однако можно дать следующие общие рекомендации:.
- интерпретируемый ЯП крайне рекомендуется писать на компилируемом ЯП (C, C++, Swift). Иначе потери производительности будут расти как снежный ком, пока мета-интерпретатор интерпретирует ваш интерпретатор;
- компилируемый ЯП можно писать на интерпретируемом ЯП (Python, JS). Возрастёт время компиляции, но не время выполнения программы.
Проектирование архитектуры
В структуре языка программирования есть несколько этапов от исходного кода до исполняемых файлов, каждый из которых имеет определенный способ форматирования данных, а также функции для перемещения между этими этапами. Давайте поговорим об этом более подробно.
Лексический анализатор / лексер

Строки исходного кода проходят через лексикограф и преобразуются в список точек.
Первым шагом для большинства языковых аналитиков является лексический анализ. Проще говоря, это анализ текста в токене, то есть языковых единиц (переменных, имен функций (идентификаторов), операторов и чисел). Таким образом, если на вход лексикографу подается алфавитно-цифровой с исходным кодом, то получается список всех лексем в нем.
Исходные коды больше не будут упоминаться на следующем этапе, поэтому лексикографу необходимо извлечь всю необходимую для них информацию.
При создании языка первое, что я сделал, это написал лексикограф. Позже я исследовал инструменты, которые могли бы облегчить лексикографический анализ и уменьшить количество возникающих ошибок.
Одним из наиболее важных таких инструментов является Flex, генератор лексического анализатора. Он берет файл с описанием грамматического языка и создает программу на языке C. Эта программа анализирует струны и выдает желаемый результат.
Моё решение
Я решил оставить написанный мною анализатор. В итоге я не увидел особых преимуществ во Flex, а использование Flex только создало дополнительные зависимости, которые усложнили производственный процесс. Кроме того, он обеспечивает большую гибкость. Например, операторы могут быть добавлены в язык без необходимости редактирования нескольких файлов.
Синтаксический анализатор / парсер
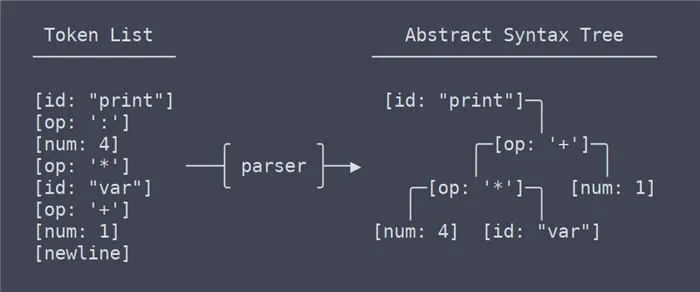
Список лексем проходит через анализатор и преобразуется в дерево.
Следующий шаг — аналитик. Он преобразует исходный текст, т.е. список лексем (с учетом скобок и последовательностей операций), в абстрактное дерево синтаксиса, которое позволяет структурно представить правила создаваемого языка. Сам процесс можно описать как простой, но по мере увеличения количества языковых структур процесс становится намного сложнее.
Bison
Для этого шага мы также рассмотрели возможность использования сторонней библиотеки, чтобы позволить Bison создавать анализ. Это очень похоже на Flex. Файл анализа пользовательских правил структурирован с помощью программы на языке C, но опять же, мы отказались от средств автоматизации.
Преимущества кастомных программ
С lexer мое решение создать и использовать собственный код (около 200 строк) было очень очевидным. Я люблю вызов, и это тоже относительно неважно. Для синтаксического анализатора это совсем другая история. Сейчас его код состоит из 750 строк, и это его третья попытка (первые две были просто неприемлемы).
Тем не менее, я решил провести собственный анализ. Основные причины следующие.
В целесообразности этого решения меня убедило высказывание Уолтера Брайта (создателя языка D) в одной из его статей:.
Рекомендуется не использовать редакторы словарей, генераторы аналитики или другие «компиляторы». Составление словаря редакторами и аналитиками не занимает много времени. Использование генераторов фиксирует вас в будущем (что важно при переносе компиляторов на новую платформу). Генераторы также печально известны тем, что выдают нерелевантные сообщения об ошибках.
Мне позвонила подруга и сказала, что ее сын был очарован Толкиеном и мечтал придумать свой собственный язык, но она не знала, с чего начать. Вскоре у меня в голове появились разные способы, и я решил поделиться ими.
Варианты посложнее
Мне приходится думать о двух китах: лексике и грамматике. Во-первых, словарный запас. Рассмотрим само слово, вы можете просто создать различные наборы символов.
Например, ‘Corgodnal’ — это школа. Например, «Тируш» будет работать. Или даже «тиррррус». Не показывайте, что это глаголы, например, «Tirrrrrrrrrrrrrrrrrrrrrr». и «Квак». Оно означает «сейчас». Как только вы найдете эти слова, запишите их в тетрадь и создайте специальный словарь для придуманного языка.
Итак, у вас есть словарный запас. Теперь вы должны строить предложения на его основе. Помните, что основная функция языка — это общение. Поэтому приходится придумывать фразы и рассказывать их друзьям. Что вам нужно; вам нужна грамматика! Он помогает словам соединяться друг с другом в предложениях.
Как и почему я решил изучать Elv (и написал руководство).
На русском языке: «Мы сейчас бегаем по школе. Нам не хватает «мы»! Вы можете быть похожи на древнего римлянина или современного испанца. В обоих случаях используются глаголы для объявления действующих лиц. Например, испанцы говорят «como» — они дают понять, что я «ем», а не просто «ем». Точно так же римляне говорили: «non scolae sed vito discaimus».
Поэтому мы говорим: «Я руковожу школой».
Тираш — кто баллотируется? Английский язык. Есть ли личный конец? ‘run’ означает «я бегу» и «бежать». Изменение происходит только в единственном числе. Оставьте себе «тириш».
Теперь нам нужно добавить «из школы». Да, нам не хватает намерения! Давайте сделаем это. Скажем, «прыжок». Возможно, слово «коргодналл» следует изменить. Или нет? Это опять английский? (Здесь и студенты жалуются, что он сложнее русского!). В английском языке форма слова не меняется. ‘At school’ означает ‘в школе’, а ‘near school’ означает ‘рядом со школой’.
Давайте оставим все как есть! ‘Тируш Пис Коргодналл Кряпа’.
Сумасшедший. Есть фразы на придуманном языке!
- Словарик для записей.
- Знание других языков (чтобы ориентироваться).
- Употребление выдуманных нами слов (без практики всё улетучится).
Если трудно придумать словарь, возьмите слова из древних языков или английского. Например, Джоан Роулинг придумала весь язык заклинаний «Гарри Поттера» на основе латыни. В мультсериале «Куми-Куми» также используется смесь языков, например, «Лака-Лака» (мне нравится). — Из Японии же «shtu-druka» и «Zaka-byaka» — это, конечно, нелепые русские слова.
Конструирование языка — полезное занятие! Она помогает творчески подходить к языку, развивает системное мышление (вся грамматика — это система!). ), а также помогает укрепить ваши отношения. Как прекрасно говорить с друзьями на своем тайном языке! Также здорово иметь такой язык только для своей семьи. Это секретный код, который сохраняется в течение нескольких лет и объединяет всю семью, даже когда дети вырастают и находят язык для своих собственных детей.
Итак, мы рассмотрели, как создать свой собственный язык, используя пошаговые инструкции по созданию собственного языка в телеграммах для мобильных телефонов. Чтобы создать уникальный перевод, необходимо воспользоваться специальным сервисом разработчика мессенджера. Она доступна каждому и абсолютно бесплатна. У вас есть вопрос по теме материала? Тогда зайдите в комментарии и спросите!
Компилятор
Компилятор — это программа, которая преобразует текст языка в машинный или другой язык. Программа-игрушка для этого семинара компилируется в LLVM IR (IR для промежуточного представления), который затем редактируется в машинный язык.

LLVM можно использовать для оптимизации процесса компиляции без необходимости учиться оптимизировать его. LLVM имеет очень хорошую библиотеку для работы с компиляторами.
Наш компилятор можно разделить на три компонента.
- лексический анализатор (лексер, англ. lexer)
- синтаксический анализатор (парсер, англ. parser)
- генератор кода
Rply, который очень близок к Ply, используется для лексикографа и аналитика. Это библиотека Python с тем же словарем и инструментами разрешения, но с улучшенным API. Для генератора кода компонент LLVM подключается с помощью LLVMLite, который является LLVM Lite.
Лексический анализатор
Поэтому первым компонентом компилятора является лексический анализатор. Роль этого элемента заключается в разбиении текста на пункты.

Используйте последнюю структуру примера RBNF для поиска лексем. Рассмотрим команду: .
Лексический аналитик должен разбить эту строку на следующий список лексем
Напишите код регистратора. Сначала создайте файл lexer.py с кодом для установки лексем. Используйте класс Lexergenerator в библиотеке Rply для создания лексерного аналитика.
Создайте файл main.py. В этом файле объедините функции трех элементов компилятора. Сначала зайдите в созданный вами класс Lexer и определите маркер однострочной программы.
Когда вы запустите файл main.py, в выводе вы увидите вышеуказанный токен. Вы можете переименовать бренды, но лучше оставить их как есть, чтобы облегчить координацию с функцией аналитики.
Синтаксический анализатор
Вторым компонентом компилятора является аналитик. Его роль заключается в анализе текстового материала. Этот компонент принимает список лексем в качестве точки входа и создает абстрактное синтаксическое дерево (AST) в качестве выхода. Поскольку это понятие сложнее, чем представление о списке символов, рекомендуется изучить хотя бы принципы работы аналитики и дерева редактирования по ссылкам выше.

Для реализации аналитики используйте структуру, созданную на этапе Rply. К счастью, аналитики RPLY используют форму, похожую на RBNF. Самое сложное — подключить аналитиков к Rply, но как только вы поймете идею, это станет действительно механическим процессом.
Сначала создайте файл ast.py. Он содержит все классы, которые аналитик может вызвать для создания AST.
Во-вторых, необходимо создать самого аналитика. Для этого используйте класс Parsergenerator из библиотеки rply в новом файле parser.py, а также lexer.
Наконец, файл Main.py обновляется, чтобы объединить функции аналитика и словарного аналитика.
Когда вы запускаете Main.py, вы получаете цену 6. И это действительно «Печать (4 + 4-2)?». Это соответствует линейной программе под названием. .
Таким образом, используя эти два элемента, был создан функциональный компилятор, интерпретирующий игрушечный язык. Однако компилятор все равно не создает исполняемый машинный файл и не оптимизирует его. Следовательно, самая сложная часть семинара — создание кода в LLVM.