Примечание: Экспортированный документ содержит весь текст, распознанный программой. Сюда входит нежелательный или неправильно распознанный текст.
Как скопировать текст с фотографии для дальнейшего редактирования: обзор сервисов и специализированных программ
Здравствуйте, уважаемые любители и пользователи графических компьютеров. Вам может понадобиться скопировать текст из источника. В этом нет никакой проблемы, но иногда таким источником является изображение (графический файл), что может сильно усложнить ситуацию. И многие хотят знать, как скопировать текст с изображения и есть ли в современных инновационных технологиях такая функция?
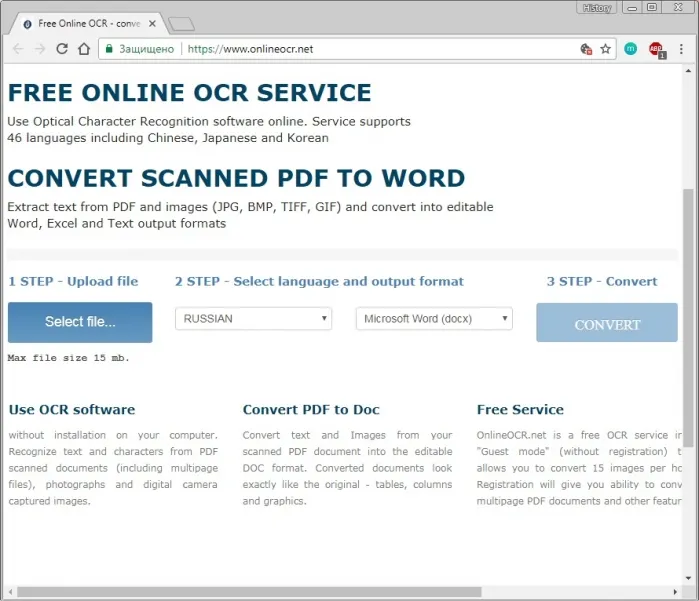
Конечно, вы можете ввести материал вручную, но что произойдет, если текст будет слишком длинным? В этом случае обратитесь за помощью в службу ЛАРН (http://www.onlineocr.net). OSR (английское название: производное от Optical Character Recognition) — это набор методов или программного обеспечения для распознавания символов и полных текстов в файлах растровых изображений.
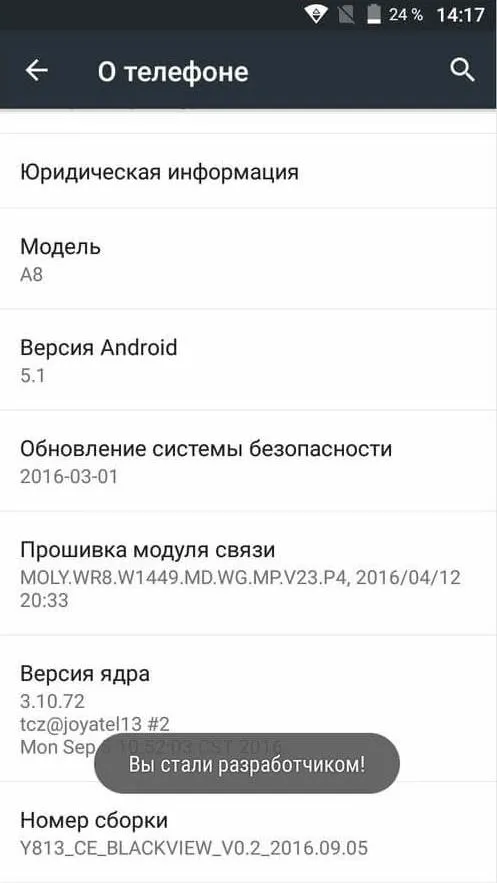
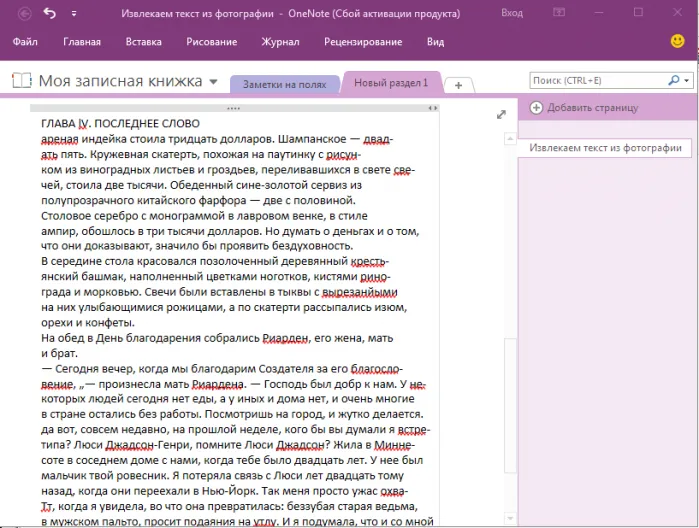
Например, скопируем текст предыдущего сообщения. Я сделал скриншот сообщения ns на главной странице. Вот:.


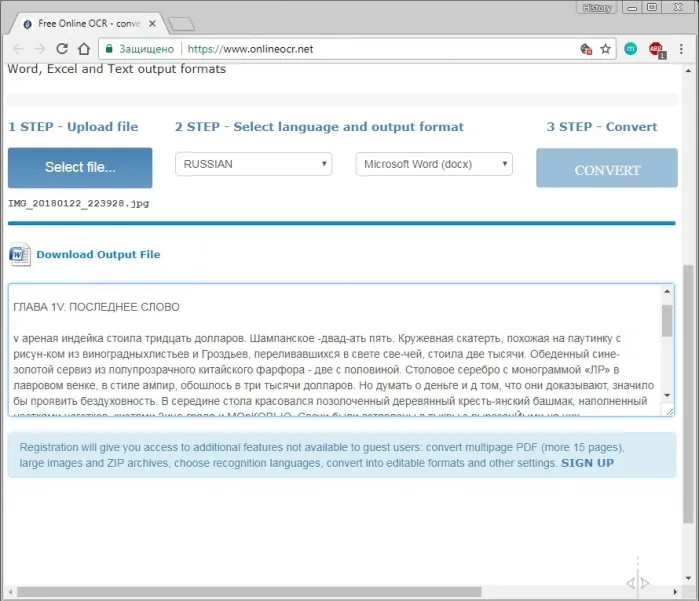
- Загружаем его в сервис OCR, нажав на кнопочку «Select file» и выбираем путь к данному файлу.
- Выбираем язык на котором написано на выбранном изображении. В моем случае «Russian».
- Выбираем тип файла, в который сохранится запись – Microsoft Word (docx). Всего доступно три типа файлов: word, exel и обычный txt.
- Далее вводим CAPCHA и нажимаем кнопочку «CONVERT».
Подождите некоторое время, пока служба обработает файл. Здесь: все копируется до тех пор, пока все не станет «улыбаться». )
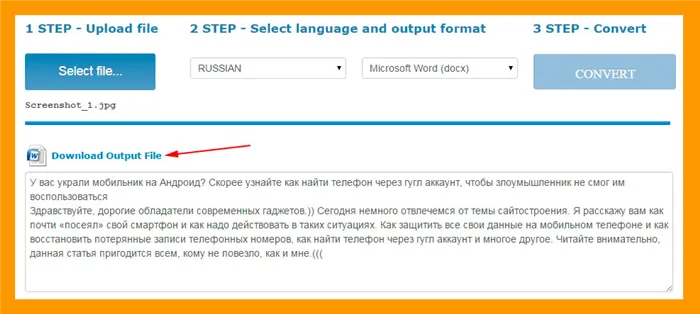
Затем вы можете нажать кнопку Загрузить выходной файл, чтобы загрузить текст на ваш компьютер в виде текстового файла Word.
Копирование текста с картинки в Интернет браузере
Первый инструмент, который мы рассмотрим, — это ProjectNaptha, дополнение для браузера GoogleChrome. Это бесплатное и очень простое в использовании дополнение, которое позволяет легко копировать информацию с графического изображения (без запуска другой программы) в любое время. Он распознает текст с отфотошопленных изображений и фотографий.
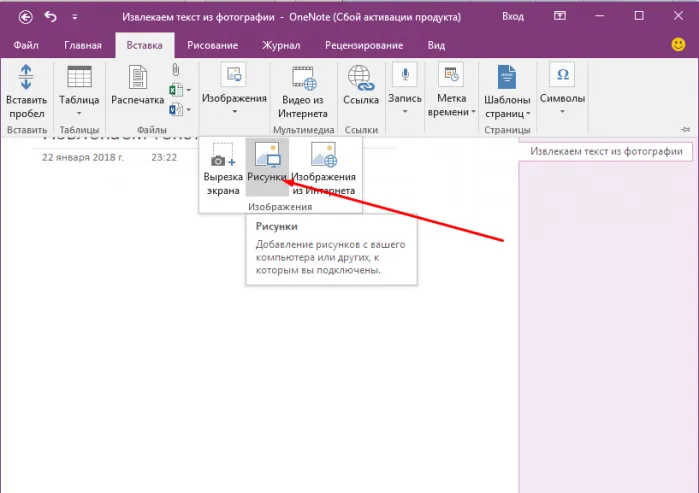
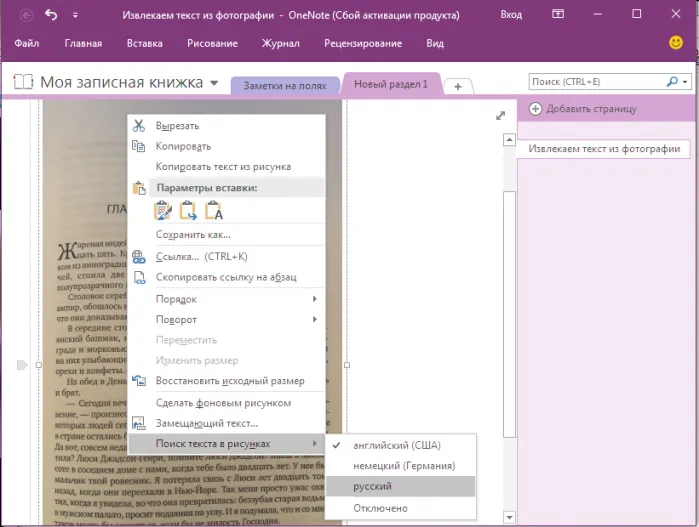
После установки (меню… Другие расширения… Больше расширений… Поиск проекта «Нафта»… Импорт… Установить…) В документах с растровыми изображениями надстройка всегда активна.
Дополнение распознает почти все шрифты. К сожалению, у него есть недостаток: он не может работать с некоторыми символами. Копирование информации, содержащей определенные символы, такие как «апостроф», может привести к появлению сообщения об ошибке.
Другие программы OCR

Одной из таких программ является ABBYYFineReaderProfessional 12. К сожалению, она не бесплатна, но вы можете установить бесплатную 15-дневную пробную версию.
Эта программа предлагает гораздо больше функций, чем вышеупомянутые плагины. Помимо всех прочих функций, он предлагает возможность конвертировать данные из PDF в файлы DOC в программе Word. Программа также распознает буквы и символы.
Мы обнаружили неработающую версию 11 этой программы. Работает без проблем. ABBYYFineReader 11 можно скачать бесплатно здесь.
Это классная и проверенная программа. Я бы посоветовал вам использовать себя. Не раз он выручал меня в трудных ситуациях.)))
Примечание: ABBYY FineReader позволяет сохранять текстовые документы на компьютере, а также экспортировать их в облачные хранилища и другие сервисы. К ним относятся BOX, Dropbox, Microsoft OneDrive, Google Drive и Evernote.
Скопировать текст с фото – зачем это нужно и как это сделать
Постоянная работа с текстовой информацией часто предполагает использование изображений, которые представлены в увеличенном формате. С одной стороны, достаточно переписать слово в слово и посвятить этому несколько минут времени. Но для профессионалов, работающих с широким спектром изображений (впрочем, и для обычных пользователей), эта задача может превратиться в часы пыток. Существует множество способов копирования текста с фотографии. В этой статье анализируется, какие из них стоит использовать.
Существует множество случаев, когда необходимо выполнить такую работу.
- В рамках ведения профессиональной деятельности специалисту передают фотографии важных документов, которые надо отразить в текстовом формате. Естественно, с сохранением форматирования.
- Под рукой есть интересная книга, которую хочется читать на смартфоне или планшете, но делать это через фотографии, естественно, неудобно. А в случае с большинством современных электронных читалок – невозможно, так как подобные устройства попросту не поддерживают просмотр изображений. Они ориентированы исключительно на текст.
- В школе, колледже или университете появилось новое расписание, которое позже приходится откорректировать, но исходная версия файла может быть утеряна, либо к ней не будет доступа.
- Уникальный текст защищен от копирования методом преобразования в изображения, и его необходимо повторно перевести в удобный для редактирования формат.
- Текст на изображении представлен на иностранном языке, в котором пользователь не ориентируется. В таком случае достаточно преобразовать изображение в текст, скопировать полученный результат и вставить в онлайн-переводчика. Делается это всего за пару-тройку минут, и не приходится тратить время на ручной ввод, да еще и на непонятном языке и без подходящей раскладки клавиатуры. Подобных ситуаций на практике масса. Но проблема одна – есть текст на фото и желание перевести его в комфортный формат с возможностью внесения правок.
Скопировать текст с фото – как это можно сделать?
Многие инструкции опубликованы в Интернете, и их авторы предлагают использовать множество различных программ и специализированных онлайн-сервисов. Есть две основные проблемы с использованием большинства из них. Первое — это необходимость платить за программное обеспечение. Вторая — помимо финансовых затрат, необходимо понять принципы работы, узнать о рабочей среде пользователя и т.д. И это проблематично и раздражает, потому что такие ситуации носят более бытовой характер и требуют немедленного решения.
Поэтому существует два варианта.
- Использование лучшего программного конвертера для персонального компьютера – программы ABBY
- Использование сервиса Google Photo.
Abby Finereader — это программа совместного использования. Здесь необходимо заплатить за лицензию, чтобы разблокировать полную версию, а платформа ограничена персональными компьютерами. С другой стороны, Google Фото — это универсальное решение, которое следует использовать с самого начала.
Скопировать текст с фото с помощью Google Photo
Использование Google Фото уже включено в пакет Google Assistant Suite. Последовательность извлечения текста из изображений следующая.
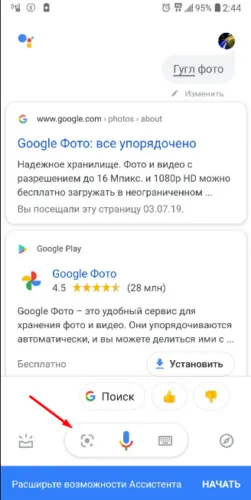
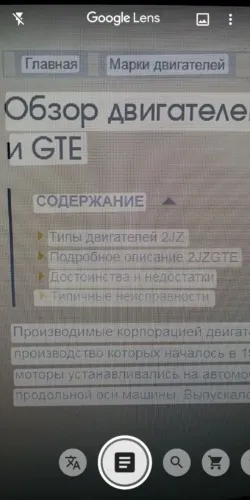
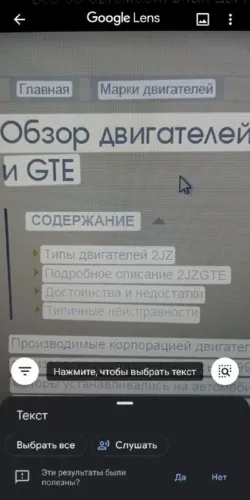
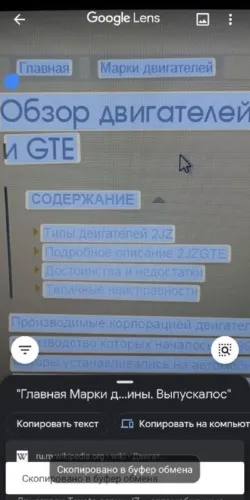
Теперь остается только отправить текст в текстовый процессор или отклонить его по своему усмотрению.
Редактор PDF совместим как со старыми, так и с новыми версиями операционных систем Windows и быстро работает на компьютерах любой мощности, не перегружая ресурсы.
Newocr.com – поможет скопировать надпись с любой картинки
Еще один качественный ресурс, о котором мы хотели бы вам сообщить, — newocr.com. Благодаря своим возможностям, он может распознавать тексты на 106 языках, является бесплатным и не требует регистрации. Пользователи Pollos могут загружать неограниченное количество фотографий, и услуга подходит для идентификации на нескольких уровнях. Полученные результаты обрабатываются в Google Docs и могут быть загружены на компьютер, где они переводятся с помощью Google или Bing Translator.
Чтобы работать с сервисом, выполните следующие действия.
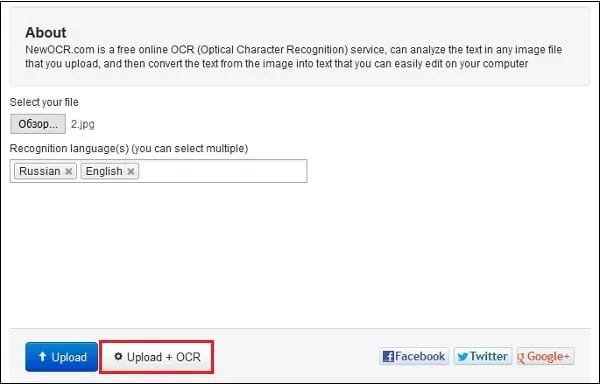
- Запустите newocr.com;
- В графе «Recognition language» (языки распознавания) выберите языки, на которых написан текст в изображении;
- Нажмите на «Обзор», и укажите сервису путь к нужному изображению;
- Для загрузки картинки на ресурс и её распознавания кликните на кнопку «Upload+OCR»;
- Просмотрите полученный результат. При необходимости с помощью рамки отметьте место в тексте, где расположен нужный для распознавания текст;
- Для его сохранения на ПК нажмите на кнопку «Download».

Нажмите кнопку Загрузить, чтобы сохранить результаты.
I2ocr.com – бесплатная идентификация текста онлайн
I2OCR — это бесплатный OCR-сервис, позволяющий распознавать текст с изображений в режиме онлайн. Его возможности позволяют извлекать текст из изображений в Интернет для обработки, формирования, индексирования, поиска или перевода. Сервис поддерживает более 60 языков, многоязычное распознавание на одном изображении, анализ документов во многих колонках и неограниченное количество бесплатных изображений для загрузки.
Чтобы работать с сервисом, выполните следующие действия.

- Выполните вход на i2ocr.com;
- В графе «Select language» выберите язык распознавания;
- Нажмите на кнопку «Select image» в центре, и загрузите изображение на ресурс;
- Поставьте галочку рядом с надписью «Я не робот»;
- Нажмите на «Extract Text» для получения результата (будет отображён внизу).
Convertio.co – ресурс для копирования надписей с изображений
Ресурс Convertio.co — популярный международный интернет-конвертер. Он может конвертировать шрифты, видео, аудио, презентации и файлы, изображения и документы. Также доступна функция OCR. Злоупотреблять этим. Десять страниц (изображений) могут быть распознаны бесплатно, за большее количество страниц взимается дополнительная плата.
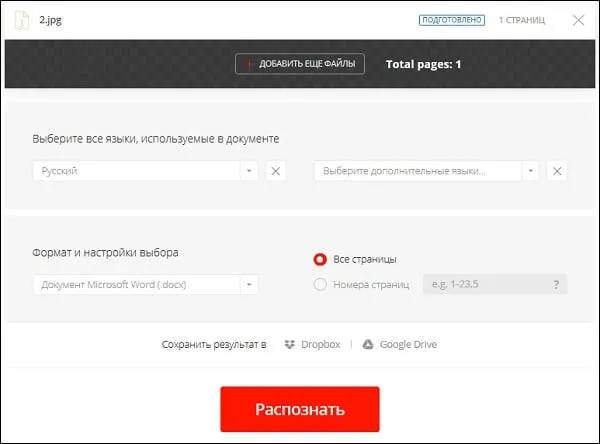
- Запустите convertio.co/ru/ocr;
- Нажмите на «С компьютера» для загрузки изображения на ресурс;
- Чуть ниже выберите язык для распознавания (при необходимости активируйте дополнительные языки). Также выберите тип документа, в который будет трансформирован распознаваемый текст;
- Нажмите внизу на «Распознать»;
- Нажмите сверху на зелёную кнопку «Скачать» для получения результата;
Дополнение распознает почти все шрифты. К сожалению, у него есть недостаток: он не может работать с некоторыми символами. Копирование информации, содержащей определенные символы, такие как «апостроф», может привести к появлению сообщения об ошибке.
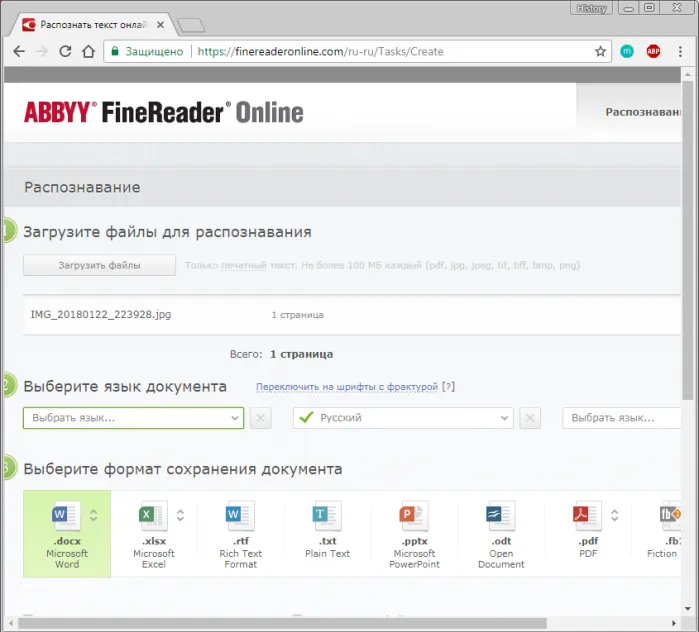
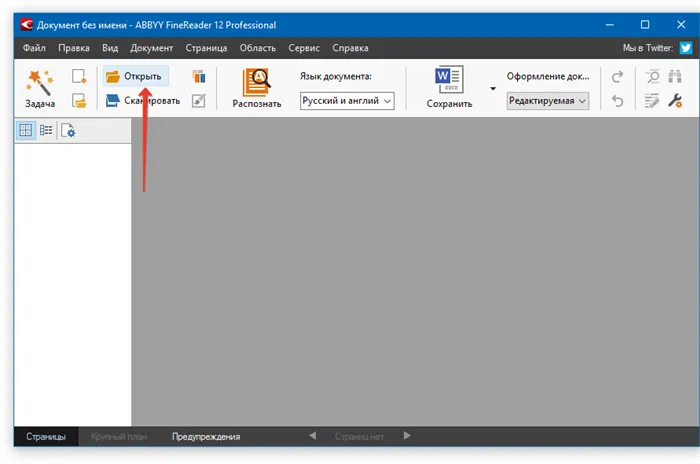
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна из них работает автоматически через Интернет, другая представляет собой таблицу и должна быть загружена и установлена на вашем компьютере. Обоим предъявлены обвинения. Однако онлайн-версия позволяет бесплатно определить до пяти страниц текста, в то время как установленная программа является бесплатной пробной версией для первого раза. На сегодняшний день это один из лучших инструментов для распознавания текста на фотографиях.
Онлайн версия
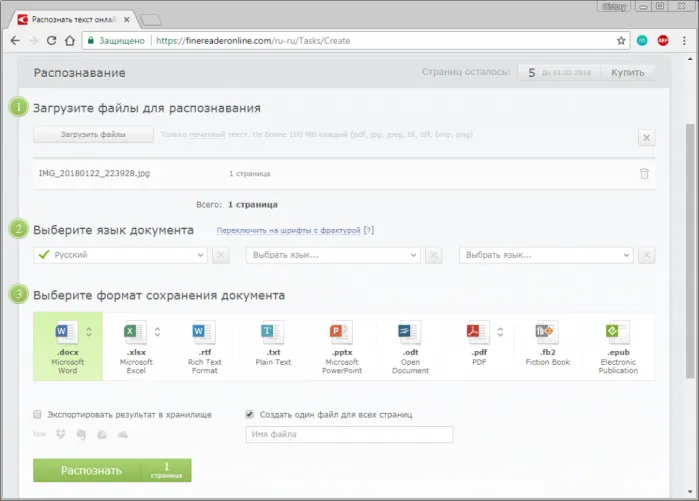
Текст сохраняется в формате документа. Скачать.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
- Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Шаг 3: Верификация. Программа имеет функцию проверки. Нажав на эту кнопку, пользователь подтверждает, что часть оригинала и часть оригинала на экране были определены неверно. Этот шаг позволяет пользователю быстро исправить почти все ошибки в программе.
Шаг 4: Сохраните текст предложенным способом.
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Видео — Как распознать PDF в Word
Сравнение популярный инструментов распознавания текста
| Название программы | OneNote | FineReader OCR Online | Free Online OCR |
|---|---|---|---|
| Условия использования | Стандартная программа, входящая в пакет Microsoft Office. Как правило, присутствует на всех компьютерах ОС Windows | Онлайн версия программы. До 5 страниц бесплатно при регистрации | Бесплатный онлайн-сервис. Не требует регистрации |
| Скорость | Мгновенное распознавание | Процесс происходит на сервере. Время ожидания не больше 5 минут | Мгновенное распознавание |
| Особенности | Это не главная функция программы, а лишь побочная. Хоть она и достаточно хороша, не ждите от нее совершенства | Сокращенная версия основной программы. В полной компьютерной версии намного больше опций, повышающих качество распознавания. Доступно распознавание теста сразу на нескольких языках, если в тексте есть вставки на другом языке. Сохраняет форматирование | Скорость. Доступность |
| Число доступных языков | В русскоязычной версии программы доступно три языка: русский, английский, немецкий | Множество языков | Множество языков |
| Результат | 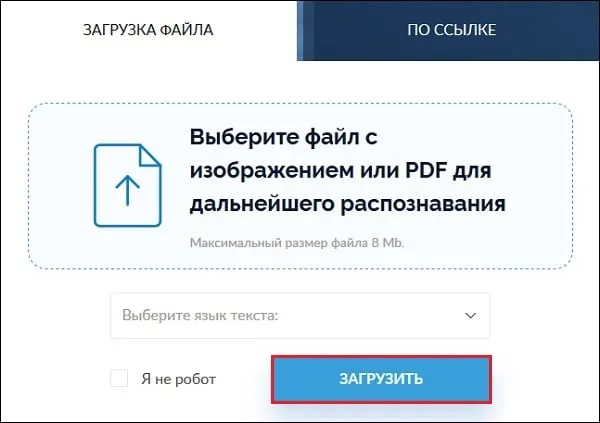 |
 |
 |
Рынок наводнен программами OCR, которые могут извлекать текст из изображений, но хорошая программа OCR должна делать больше, чем простое распознавание текста. Он должен поддерживать компоновку содержимого, текстовые шрифты и графику, как и оригинальный документ.
В Windows, Android и iOS на современном iPhone или смартфоне Android можно практически скопировать любой фрагмент текста и вставить его практически в любое место, где можно ввести текст, что позволяет сэкономить массу времени благодаря этой функции.
Бесплатный сервис по распознаванию текста из изображений
Сканируйте или фотографируйте текст для легкого распознавания
Загрузите файл
Выберите язык текста в файле
После завершения редактирования файла загрузите результаты * Время обработки файла может занять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность Сайт переведен на 9 языков
- Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 30.1M+ запросов
Основные возможности
Идентификация отсканированных файлов и фотографий, содержащих текст


Форматирование документов на бумаге и PDF в редактируемые форматы
Будь вы студент, офисный работник или крупная библиотека!
У вас есть учебники или журналы, текст которых вы хотите восстановить, но у вас нет времени набирать его?
Наш сервис помогает создавать текстовые переводы из фотографий или документов PDF. После получения результатов вы можете загрузить текст для перевода в Google Translate, конвертировать его в PDF или сохранить в формате Word.
OCR и визуальное распознавание текста еще никогда не было таким простым. Все, что вам нужно сделать, это отсканировать или сфотографировать текст, затем выбрать файл и загрузить его в сервис OCR. Если фотография текста достаточно точная, вы получите распознанный и разборчивый текст.
Услуга также позволяет преобразовать PDF-файл в изображение; вы получите ZIP-файл, который затем можно использовать для сканирования и фотографирования текста.
Эта услуга не поддерживает рукописный текст.
Поддерживаемые языки: африканский, amcharics, арабский, азербайджанский, азербайджанский — кириллица, белорусский, бенгальский, тибетский, боснийский, бретонский, болгарский, каталанский, валенси, английский, английский — средний (1100-1500), эсперанто, эстонский. Французский, баскский, фероэ, персидский, филиппинский (старый — тагалог), французский, немецкий — флак, французский, средний (1400-1600), западный фризский, шотландско-гэльский, ирландский, галисийский, греческий, древний (до 1453), гуджарати, гуджарати Хайтини, Хайтини Креоли, иврит, иврит, хинди, инуктитут, индонезийский, исландский, итальянский, итальянский — старый, ивания, японский, японская вертикаль, канадский, георгианский, георгианский — старый, Казахстан, Центральный Кхмерский, коргизский, курдский, нечаянный, лаосский, латинский, латышский, литовский, люксембургский, малаялам, маратхи, македонский, мальтийский, монгольский, маори, малайзийский, бирманский, непали, фримиш, норвежский, октана, кечуа, румынский.