скачать советы Balda Game Direct Link
ПОДСКАЗКИ К ИГРЕ БАЛДА
* файл сжат в zip-архив (exe
Название: Подсказки к игре балда
что еще искали с этим запросом:
Дополнительно к «к игре балда Подсказки»
snezhana (03:13:11 18:12:57): тестовая анкета и тестовое задание применимы к людям разного возраста, из разных культур, с разным уровнем образования, разными профессиями и разным жизненным опытом — и игра-добавление в Sims 2 Seasons.
камола (03:13:11 18:12:57): устный опрос используется в тех случаях, когда желательно наблюдать за поведением и реакцией человека, отвечающего на вопросы
варвара (03:13:11 18:12:57): в психологии начали создаваться специальные технические устройства и устройства, которые использовались для проведения лабораторных экспериментальных научных исследований, а также для интерпретации лысины.
аделаида (03:13:11 18:12:57): Это также должно включать начальный этап в развитии дифференциального психологического исследования, конец X1X в
иларион (03:13:11 18:12:57): В тестах этого типа испытуемому предлагается ряд специальных заданий, по результатам которых он оценивается по наличию или отсутствию и степени развития качество изученное в нем..
джеральд (03:13:11 18:12:57): Там, где это можно сделать, обычно наблюдается заметный прорыв в познании мира
andrej (03:13:11 18:12:57): Они отличаются друг от друга тем, что позволяют, наконец, изучать психологию и поведение людей в отдаленных или близких к реальности условиях.
олег (03:13:11 18:12:57): Следующие три раздела психологии, медицины и патопсихологии, а также психотерапии занимаются отклонениями от нормы в психике и поведении человека
Каждый день в речи мы используем кажущиеся нам знакомые слова и фразы, не задумываясь об их значении. «Балда» относится к одному из тех многозначных слов, значения которых различаются от одного контекста к другому, и одна из интерпретаций этого слова является результатом ложной этимологии.
Значение слова «балда»

Однородные толкования слова «жирный» можно найти в русских словарях. В. Даль определяет это слово следующим образом:
- большая тяжелая набалдашник (утолщение на ручке трости);
- болезненная шишка, разрастание;
- ударное оружие: то же, что и палка;
- большой молоток, кувалда;
- трамбовка;
- отруби .: дурак, дурак, неуклюжий дурак, сплетник, нарушитель спокойствия, дурак, дурак, дурак;
- балдашка — деревянная чаша для сбора и питья;
- ублюдок это как болтать, дриблинг.
По словам Д.Н.Ушакова, лысина — это:
- те термины: тяжелый молот для дробления камней и скал;
- утолщение в верхней части ствола;
- ругает: глупо, глупо.
Т. Ф. Ефремова дает следующие определения слова жирный:
- фр., устаревший — тяжелый молот, используемый в шахтах и кузницах;
- mr, f r., rasp — нижний: тот, кто тупой и тупой.
Как выиграть в игре Балда В топах игры Балда например на Mail.ru их много
1 шаг
Эти люди не просто используют свой разум, пришло время понять, что они играют и выигрывают с помощью программы-решателя.
Ссылку для скачивания вы увидите в комментариях.
Итак, скачайте этот архив с программой, распакуйте и я подробно расскажу, как использовать решатель для игры Balda.
2 шаг

Решатель для балды находится в папке «balda_solution», как нетрудно догадаться… Открываем папку, запускаем файл «Робо-юлик Balda.exe»
Начнем играть в baldon на Mail.ru (вам не обязательно использовать этот сайт, вы можете играть в baldon на любом другом сайте)
3 шаг
У нас есть открытая программа и сайт, идем дальше. В окне решателя (слева, под самим игровым полем) есть поле с уже вписанным словом «банк», вместо этого слова мы пишем слово, которое было задано игрой. И нажмите кнопку запуска.
В поле найденные слова будут выделены все возможные варианты ваших ходов, а на первых местах будут самые «выгодные» слова, выберите слово. Посмотрим в программе, как разместить вашу букву на поле, оно отмечено красным. Проверяем в игре, подходит ли он (очень и очень редко может не подходить), только после этого нажимаем кнопку с надписью «<< + b ".
4 шаг
Ждем хода соперника… Если очень часто он использует те же слова, которые указаны в программе на первых местах, убедитесь, что с вами играет человек, с такой же программой или похожей.
5 шаг
Программа показывает возможные ходы соперника… Слово с сеткой обычно считается самым выигрышным словом… Количество букв в этом слове указано в скобках.
Такую интересную и вкусную рыбу, как хариус, можно поймать не менее интересным способом — «на мяч».
Катушка

Что касается безынерционной катушки, то многие современные рыболовы вполне приспособились к ее использованию для проводки. Сам не пробовал, поэтому рекомендовать ничего не могу. Знаю, что после запуска дуга слоя лески не замыкается и леска может свободно выходить из барабана, удерживая ее рукой. При укусе лук закрывается, и добыча начинает играть. Как уже отмечалось в начале статьи, самое приятное в этой снасти — это использование инерционной катушки, а не какой-то китайской из тонкой, почти прозрачной жести, а старой доброй дедушкиной катушки, производства СССР — «Невская». Мастера модифицируют эти катушки, заменяя втулки подшипниками, тем самым устраняя люфт и приобретая катушку чудесной крутки барабана. Следовательно, именно инерционная катушка позволяет разводить проводку на большие расстояния и четко управлять ею, замедляя барабан большим пальцем рабочей руки и контролируя движение поплавка вниз по потоку.
К сожалению, про мультипликаторную катушку ничего сказать не могу. Есть желание узнать эту катушку в будущем. Как я слышал от рыбака: — «Мульт, это маневренность инерционной машины с удобством инерции». В общем, есть к чему стремиться.
На катушку, конечно же, необходимо намотать достаточное количество лески. Для Balda используется мононить, а не плетение, потому что для этого необходимо использовать как минимум два стопора, и тесьма их мгновенно разрезает, поэтому только мононить. Развернуть 100… 150 метров, конечно, можно и больше, но зачем переплачивать за лишние метры. Другое дело — безинерционная катушка, где нужно наматывать леску под самый край катушки, но в случае с этой катушкой диаметр и количество шнура передачи будут указаны на катушке. Что касается диаметра лески, то усердствовать не стоит и, на мой взгляд, вполне достаточно диаметра 0,35… 0,4 мм, более толстые лески уже ни к чему.
В последнее время все больше юных рыболовов с удовольствием осваивают классический вид снаряжения с инерционной катушкой. Многие пытаются найти настоящую легенду — Невскую спираль, что в принципе возможно. Сам подобрал снасть точно по дедовским заветам катушкой «Невская». Я научился делать забросы в стороны, делать нормальные «бородки» леской (без этого никуда), ну и распутывать их.
Алгоритм быстрого поиска слов в игре лысый Однажды в социальной сети наткнулся на игру лысого с нестандартными правилами (большие поля и сучки). Связующие в основном
Алгорифм стремительного поиска слов в игре балда
Как-то в социальной сети наткнулся на игру с нестандартными правилами (большие поля и узлы). Программы-сборщики обычно работают по типовым правилам и на полях 5×5. Следовательно, у меня был спортивный интерес к написанию моей папки, полностью адаптированной к нетрадиционным правилам. Кроме того, написать поисковую систему непросто, но можно реализовать максимально быстрый алгоритм поиска слов.

Из нестандартных правил выдается довольно увлекательный режим «узлов», в котором разрешено составлять слово, применяя букву до 2 раз (например, на скриншоте выше разрешено составлять слово ШАЛАШ , буквы Ш и А используются 2 раза). Как позже выяснилось, алгоритм ищет все слова в режиме сучков в одной и той же позиции примерно в 1,5 раза дольше, чем в классическом режиме без сучков (это не замечательно, так как варианты составления слов больше, а найденные слова длиннее). В конце статьи описанный алгоритм будет протестирован в тестовой позиции в режиме узла.
Словарь
Чтобы усложнить жизнь алгоритму, будет использован один из крупнейших словарей в аналогичных программах. В нем около 110 000 слов.
Значительную роль в алгоритме играет способ хранения словаря в памяти программы. После загрузки каждое слово записывается в структуру в виде дерева. Каждый узел этого дерева обозначает определенную букву слова и относится не более чем к 32 поддеревьям (в зависимости от количества букв в алфавите). Узел дерева в программе выглядит так:
Поле str содержит строку, в которой все буквы выходят из данного узла, размер следующего массива равен длине этой строки.
Поле str используется для поиска определенного узла среди следующего массива узлов для данной буквы. Для этого мы ввели функцию ind (), основанную на strchr():
Если k <0, то этой буквы нет в str, в отличие от next [k], она указывает на узел, соответствующий этой букве. Например, если str содержит строку «aoict», то от этого узла отходят ровно 5 поддеревьев, а next [2] ссылается на букву «и», поскольку str [2] == «e», то же самое с другими буквами.
Чтобы проиллюстрировать каждое из вышеперечисленных, я приведу пример дерева по специально подготовленному словарю, состоящему из слов:
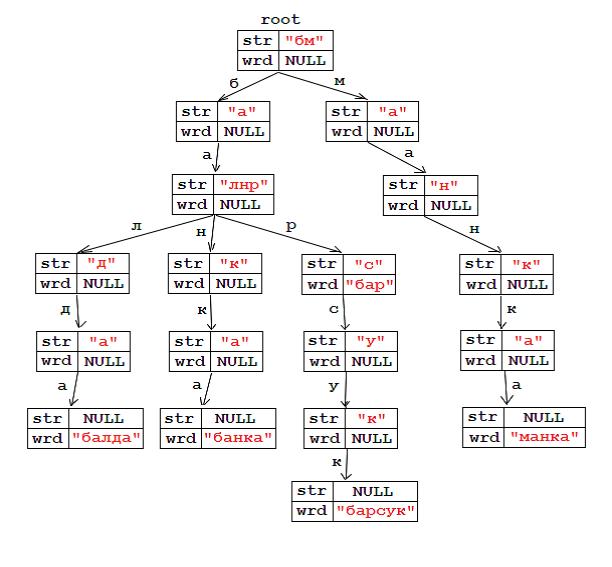
Если поле str == NULL, то этот узел является листом и содержит слово wrd. Узел, соответствующий букве «p», содержит слово «bar», и в то же время это не лист, потому что в этом словаре есть другое слово, начинающееся с bar-. Поле wrd содержит строку, которая получается при переходе от корня к соответствующему узлу, но если эта строка не является словарным словом, wrd содержит NULL .
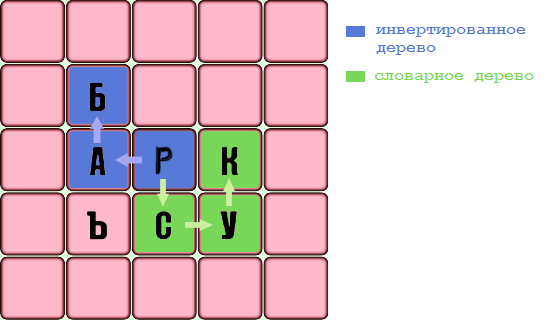
Мы называем это деревом словарей, оно содержит все словарные слова. В дополнение к словарному дереву вам необходимо подготовить еще одно, которое содержит все разрешенные префиксы перевернутых слов для любого слова (назовем его перевернутым деревом). Например, для слова «балда» в перевернутом дереве появятся следующие строки: «adlab», «dlab», «lab», «ab», «b». Даже для тестового словаря из пяти слов такое дерево будет огромным, поэтому я приведу упрощенный вариант:
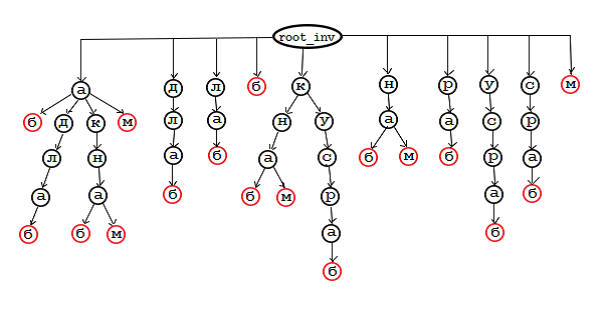
Слова Префиксы словарных слов в этом дереве расположены в обратном порядке. Узел в красном кружке соответствует последней букве перевернутого префикса словарного слова, т.е соответствует первой букве этого слова. Чтобы прочитать предисловие словарного слова, вам нужно перейти от красного узла к корню. Единственное различие между инвертированным деревом и деревом словарей состоит в том, что wrd действует как флаг (NULL / не NULL). Они не хранят строку с префиксом перевернутого слова, но:
- 1) Адрес общей строки (содержание строки не имеет значения), если этот узел совпадает с первой буквой словарного слова
- 2) NULL для всех остальных узлов.
Это сделано для экономии места. Для всех красных узлов wrd! = NULL, иначе wrd == NULL. Например:
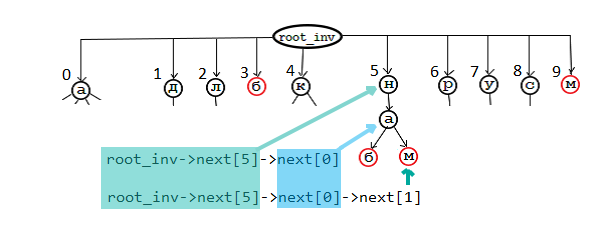
Оба дерева занимают 33 МБ памяти и легко компилируются из словаря примерно за 5 секунд на i5, поэтому было решено сохранить изображение дерева в файл и затем точно его загрузить. Таким образом, скорость загрузки составляла каждые 300 миллисекунд.
Алгорифм поиска
По правилам бульдозера для переезда нужно предпочесть пустую ячейку и поставить туда любую букву.
Затем вам нужно составить слово, используя предоставленную букву. Эта буква может быть первой буквой слова или не первой буквой (хоть заглавной, но значащей). Если правила гласят, что помещаемая буква должна быть первой, то мы можем легко использовать словарное дерево, перемещаясь по полю от буквы, одновременно спускающейся с дерева. Но поскольку данная буква может быть не первой, дерево словарей использовать нельзя, потому что вы не знаете, с какого узла начать поиск. Но у нас все еще есть перевернутое дерево.
Идея такая: из ячейки с заданной буквой мы перемещаемся по полю, спускаясь с перевернутого дерева. Если мы найдем узел с wrd! = NULL (алый узелок), то это действительный префикс перевернутого слова. Имея префикс слова, можно найти узел, соответствующий данной букве в словарном дереве, и, таким образом, легко «найти» оставшуюся часть ближайшего слова в словарном дереве, начиная с этого узла.
Чтобы алгоритм не вставлял ранее переданные ячейки по заданному слову, в каждой ячейке есть счетчик использования подсчета. Перед началом поиска этот счетчик инициализируется цифрой 2 (для режима узла) или 1 (для классического режима) — это большая разница с точки зрения алгоритма.
Более подробный алгоритм:
- 1) Перебираем все соседние пустые ячейки
- 2) Для каждой ячейки перебираем все буквы алфавита (32 буквы)
- 3) Введите текущую букву s в текущую ячейку (пусть ее координаты будут [x, y]). Таким образом, мы получаем 32 * n разных позиций, где n — количество соседних ячеек в исходной позиции
- 4) Введенная буква считается первой буквой для инвертированных префиксов.
Следовательно, между root_inv-> next мы находим узел t_inv, соответствующий текущей букве, то есть t_inv является поддеревом, начинающимся с текущей буквы:
Конечно, после буквенного цикла мы удаляем текущую соседнюю ячейку.
Функция поиска в поддереве поиска берет игровую доску, узел дерева и координаты ячейки (i, j), от которой начинается движение по полу, спускаясь с дерева дерева :
- 1) Если tree-> wrd! = NULL, найдена допустимая подстрока
- а. Если этот узел принадлежал дереву словарей, тогда эта подстрока обычно является словарным словом, добавьте tree-> wrd к массиву обнаруженных слов.
- б. Если узел принадлежал инвертированному дереву, эта подстрока является префиксом инвертированного слова. В дереве словарей мы находим узел t, соответствующий этому префиксу, и вызываем функцию поиска для вашей ячейки [x, y] (внимание! Не ячейка, которая была передана этой функции, а ячейка, в которую он перешел по алгоритму на шаге 3):
- а. Если он пуст, переходите к шагу (3)
- б. Если буквы в этой ячейке нет в tree-> str, переходите к шагу (3)
- c. Если подсчитывается [i1, j1] == 0, переходите к шагу (3)
- d. Напротив, перейдите к шагу (5)
Посмотрим, как работает алгоритм для центральной ячейки на примере дальнейшего положения:
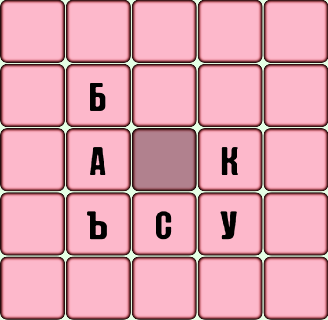
Мы помещаем в эту ячейку любую букву из строки «adlbcnrusm» (остальные буквы алфавита нелегко существуют в root_inv-> str, и алгоритм для них быстро завершится, даже не запустившись). Для каждой буквы звоните find. Для буквы A функция завершится быстро, потому что в перевернутом дереве нет ветвей, начинающихся с AA-, AC- и AKU-, то же самое верно для D, K, Y, C .
Допустимые префиксы будут найдены для остальных букв в перевернутом дереве:
Л — лаборатория, Б — б, Н — наб, Р — подчиненная, М — м. Для каждого префикса мы находим узел в дереве словарей (как описано в разделе 1.b) и вызываем для него функцию поиска .
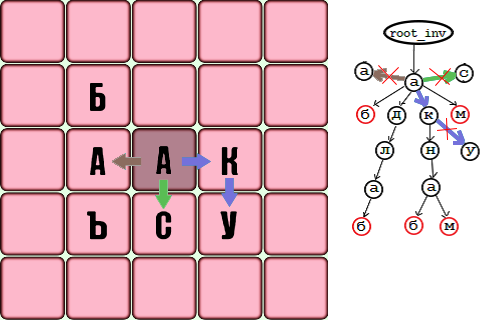
Префикс «мяч» соответствует корневому узлу -> next [0] -> next [0] -> next [0] :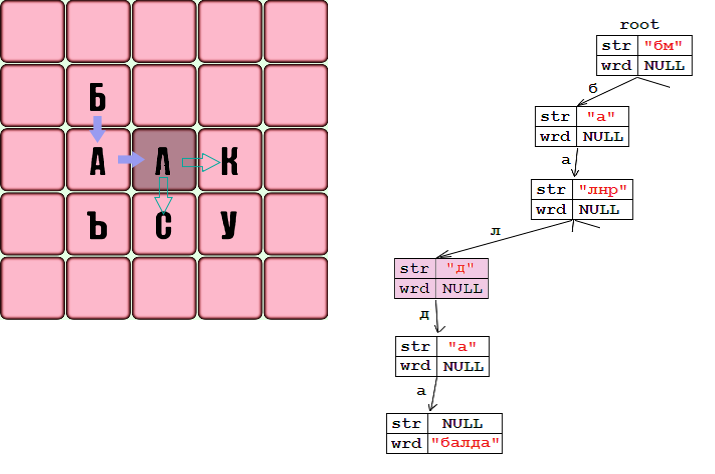
Следующая соседняя буква может быть C или K, но поле str этого узла содержит «d», поэтому мы немедленно завершаем функцию поиска, т.е в дереве нет ветвей, начинающихся с BALS- и BALK-. Для префикса «b» в дереве словарей нет ветвей, начинающихся на БК-, БС-, BAB-, BAB-, то же для префиксов «бан» и «m” .
Префикс «bar» соответствует корневому узлу -> next [0] -> next [0] -> next [2] .
Почему поле wrd! = NULL, вставить строку wrd (BAR) в массив найденных слов и продолжить поиск. Нет ветвей для строк BARK и BARS, доделываем функцию поиска для них, но строка BARSUK содержится в дереве, вставляем ее в массив обнаруженных слов.Итоги
Алгоритм был протестирован в другом поле (точнее, не в тестовом словаре, а в словаре из 110000 слов):
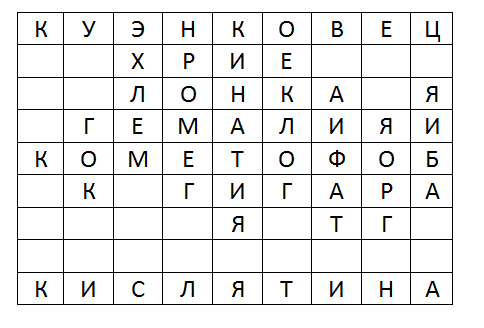
Это действительно сыгранная роль.
Вот поле 9×9, и оно наполовину заполнено (это, вероятно, одна из худших позиций для любого алгоритма, потому что есть несколько ячеек, к которым вы можете перейти, и довольно удачное взаимное расположение букв, поэтому многие длинные слова могут быть сделано). В режиме узла алгоритм находит все слова за следующее время:- 1) Mac mini i7 — 7 миллисекунд (не в собственном приложении, а в эмуляторе iPhone)
- 2) Комп от i5 — 12 миллисекунд
- 3) iPad 4 — 30 миллисекунд
- 4) Samsung Galaxy Ace (3-летняя сталь) — 50 миллисекунд (с использованием NDK)
Для других мест время поиска еще меньше.
Приложение
Этот алгоритм применяется в приложениях для iOS (доступно в магазине приложений) и Android. Помимо поиска по всем словам, реализованы два других типа поиска:
- 1) Локальный поиск: если пользователю отчаянно нужно заполнить определенную пустую ячейку (например, ячейку приза или покрыть ячейку слишком большим количеством длинных слов), дважды нажмите на эту ячейку, и программа будет искать только те слова, которые могут быть внутри
- 2) Проверка замен: двойное нажатие на букву заставит программу обнаруживать все слова, проходящие через эту букву. Использование: Сразу после хода спортсмена проверьте его букву (внезапно жестко заменяет себя), перед его ходом проверьте намеченный ход для сета
Еще одна особенность: одинаковые по длине слова сортируются по редкости добавленной буквы (например, идти с буквой выгоднее, чем с буквой А).
Источники
- http://www.votas.ru/FS/games/09-04-games/Podskazki-k-igre-balda.html
- https://nameorigin.ru/417443a-balda—eto-znachenie-slova
- http://akak.ru/recipes/14735-kak-vyiigryivat-v-igre-balda
- https://easytravelling.ru/vsya-ryba/lovlya-hariusa-na-baldu.html
- http://bb3x.ru/blog/algorifm-stremitelnogo-poiska-slov-v-igre-balda/